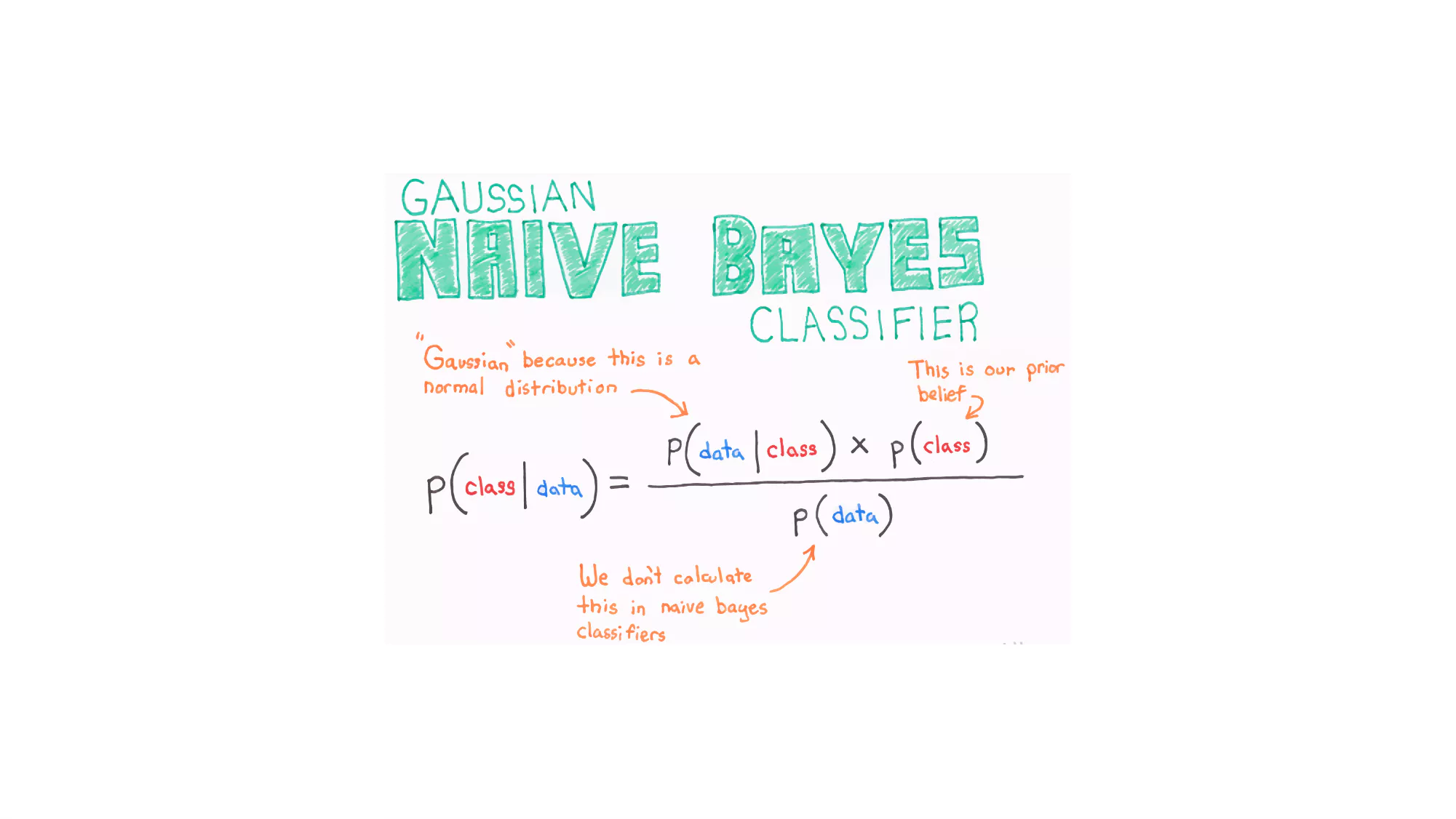
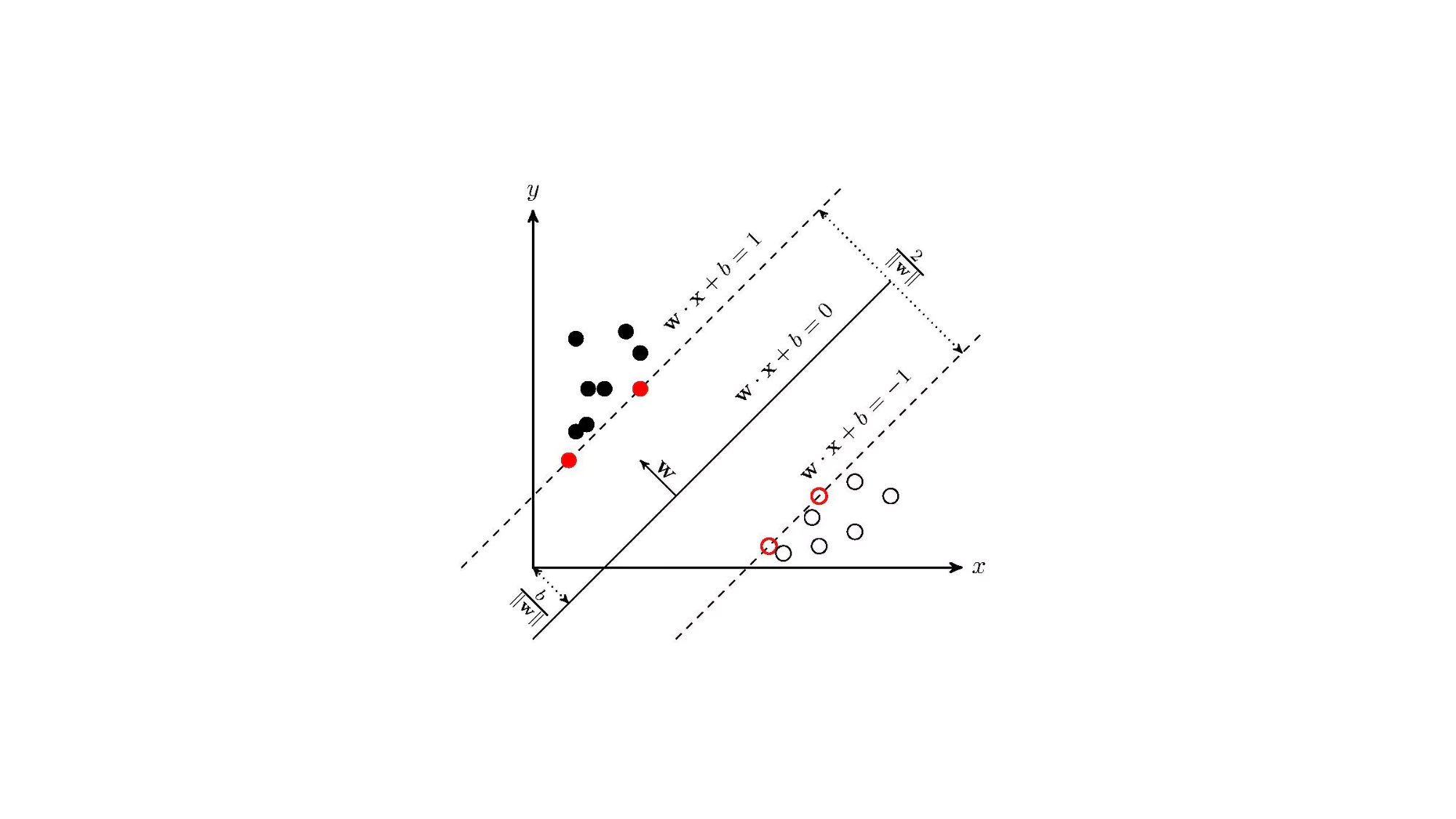
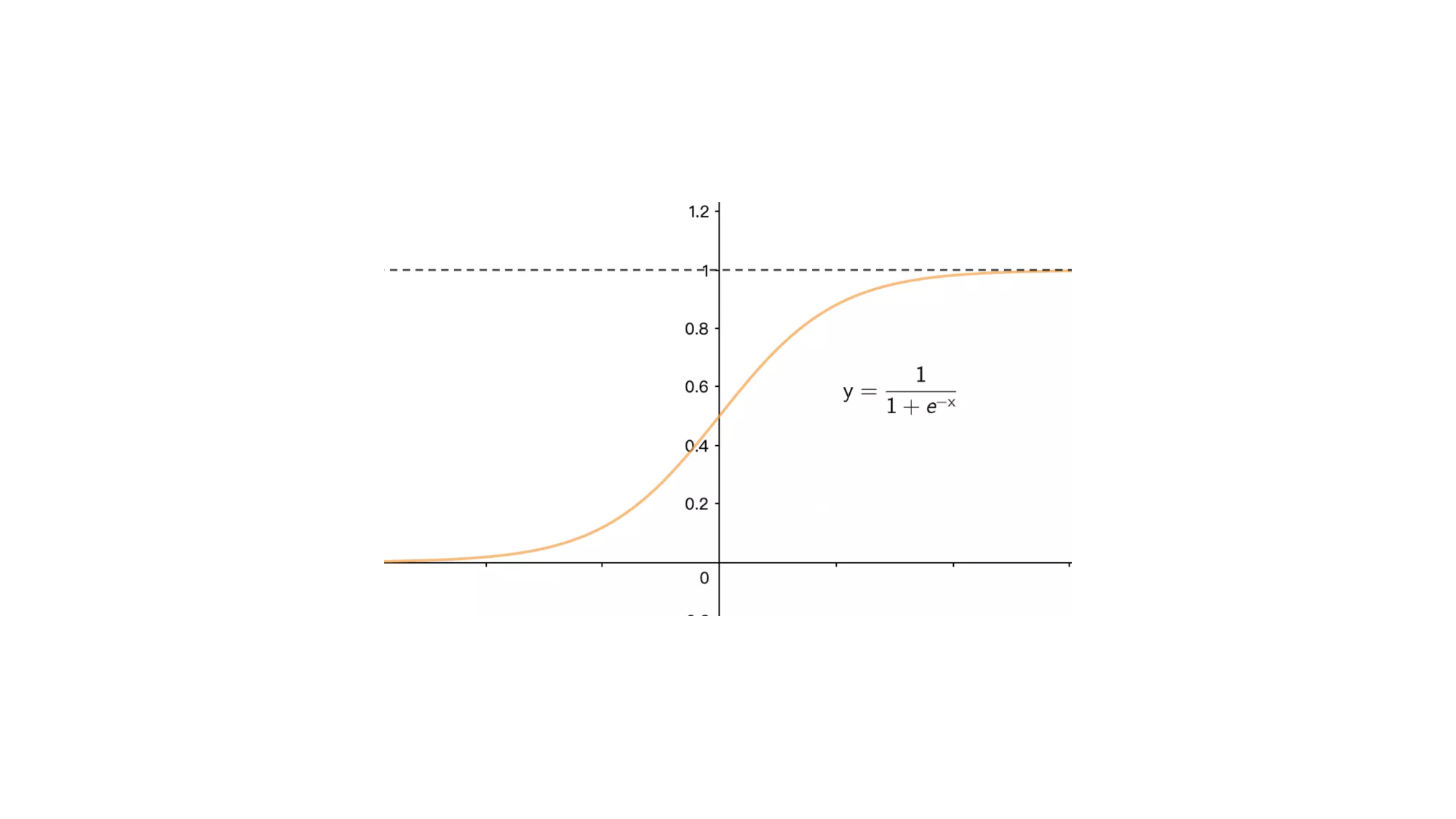
天猫复购预测-挑战赛——Top 0.5%根据原数据构建了67个特征,尝试了多种算法和多次参数调优最终得分0.6925,记录过程分享一下。感觉数据指标还可以再优化,调参也还有进步空间,可以进一步优化提升。
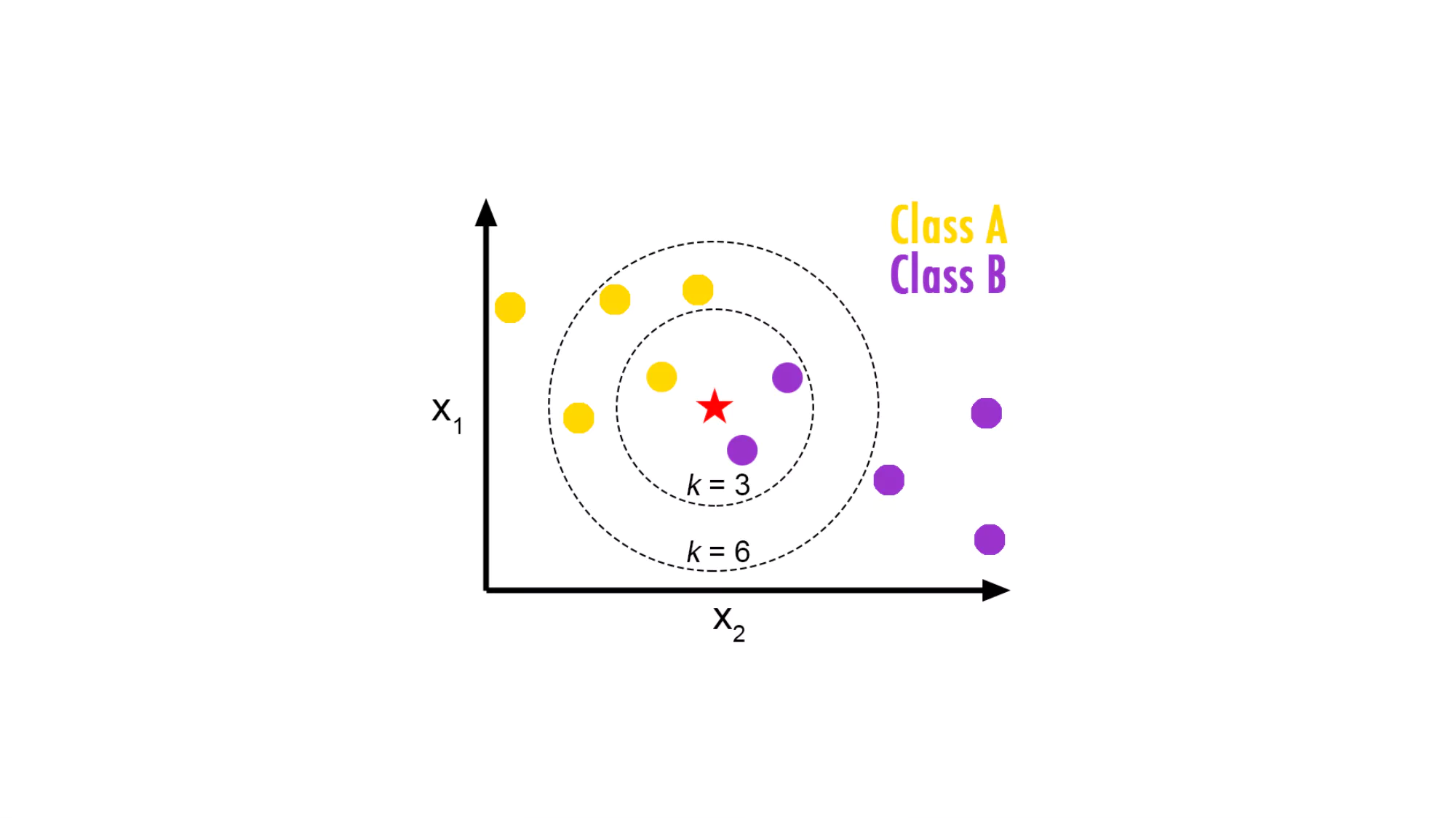
K近邻 | K-Nearest NeighborsK近邻算法 ,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。