朴素贝叶斯 | Naive Bayesian Model
type
Post
date
May 15, 2020
summary
朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。
category
学习笔记
tags
分类算法
贝叶斯
朴素贝叶斯
Bayesian
password
URL
Property
Jun 20, 2025 01:47 AM
1、相关概念
贝叶斯定理
贝叶斯定理(英语:Bayes' theorem)是几率论中的一个定理,描述在已知一些条件下,某事件的发生几率。通常,事件A在事件B已发生的条件下发生的几率,与事件B在事件A已发生的条件下发生的几率是不一样的。然而,这两者是有确定的关系的,贝叶斯定理就是这种关系的陈述。贝叶斯公式的一个用途,即透过已知的三个几率而推出第四个几率。
条件概率公式
表示X和Y一起出现的概率,称为X,Y的联合概率; 表示Y发生的条件下X发生的概率, 表示X发生的条件下Y发生的概率,这俩个称为X,Y的条件概率;
1、如果 X 和 Y 相互独立,则有条件独立公式:
2、条件概率公式:
3、根据条件概率公式可以推导出贝叶斯公式:
贝叶斯公式
的意思是在B事件发生的条件下A发生事件的概率
接下来我们通过两个例子来更好的理解贝叶斯公式
例1:现分别有 甲,乙 两个容器,在容器 甲 里分别有 7 个红球和 3 个白球,在容器 乙 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器 甲 的概率是多少?
选中甲容器的概率:
选中红球的概率:
甲中红球的概率:
选中的红球是甲中的概率:
例2:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
狗叫的概率: P(A) = 3/7
被盗的概率: P(B) = 2 / (20*365)
被盗时狗叫的概率: P(A|B) = 0.9
狗叫时被盗的概率:
将贝叶斯公式 用到我们的数据分析中则可以理解为,B是特征, A是对应的类别;
2、朴素贝叶斯的模型
训练模型
假设现有样本:
即有 m 个样本,每个样本有 n 个特征,特征输出有 K 个类别,定义为C1,C2,...,CK
根据现有样本,我们能得到每个类别K的概率:
同时可以学习到学习到条件概率分布:
然后联合概率分布为:
从上面的式子可以看出比较容易通过最大似然法求出,得到的就是类别在训练集里面出现的频数。但是很难求出, 这是一个超级复杂的有 n 个维度的条件分布。朴素贝叶斯模型在这里做了一个大胆的假设,即 X 的 n 个维度之间相互独立,这样就可以得出:
从上式可以看出,这个很难的条件分布大大的简化了,但是这也可能带来预测的不准确性。你会说如果我的特征之间非常不独立怎么办?如果真是非常不独立的话,那就尽量不要使用朴素贝叶斯模型了,考虑使用其他的分类方法比较好。但是一般情况下,样本的特征之间独立这个条件的确是弱成立的,尤其是数据量非常大的时候。虽然我们牺牲了准确性,但是得到的好处是模型的条件分布的计算大大简化了,这就是贝叶斯模型的选择。
开始预测
现在给定测试集的一个新样本特征()我们如何判断它属于哪个类型?既然是贝叶斯模型,当然是后验概率最大化来判断分类了。我们只要计算出所有的 K 个条件概率, 然后找出最大的条件概率对应的类别,这就是朴素贝叶斯的预测了。
预测的类别是使最大化的类别,数学表达式为:
由于对于所有的类别计算 时,上式的分母是一样的,都是,因此,我们的预测公式可以简化为:
接着我们利用朴素贝叶斯的独立性假设,就可以得到通常意义上的朴素贝叶斯推断公式:
参数估计
到这里只要求出 和 我们通过比较就可以得到朴素贝叶斯的推断结果。
对于比较简单,通过极大似然估计我们很容易得到为样本类别出现的频率,即样本类别出现的次数除以样本总数 。
对于, 这个取决于我们的先验条件:
如果是离散值
那么我们可以假设符合多项式分布,这样得到是在样本类别中,特征出现的频率。即:
其中为类别的在所有样本中的计数, 表示在类别为的样本中,第j维特征 出现的计数。
某些时候,可能某些类别在样本中没有出现,这样可能导致为 0,这样会影响后验的估计,为了解决这种情况,我们引入了拉普拉斯平滑,即此时有:
其中λ 为一个大于 0 的常数,常常取为 1。为第 个特征的取值个数。
如果是非常稀疏的离散值
如果我们我们的是非常稀疏的离散值,即各个特征出现概率很低,这时我们可以假设符合伯努利分布,即特征出现记为 1,不出现记为 0。即只要出现即可,我们不关注的次数。这样得到是在样本类别中出现的频率。此时有:
此时的取值为0和1
如果是连续值
我们通常取的先验概率为正态分布,即在样本类别中,的值符合正态分布。这样的概率分布是:
其中和是正态分布的期望和方差,可以通过极大似然估计求得。为在样本类别中,所有的平均值。为在样本类别中,所有的方差。对于一个连续的样本值,带入正态分布的公式,就可以求出概率分布了。
3、朴素贝叶斯实例
现有以下数据,如果一对男女朋友,男生向女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?

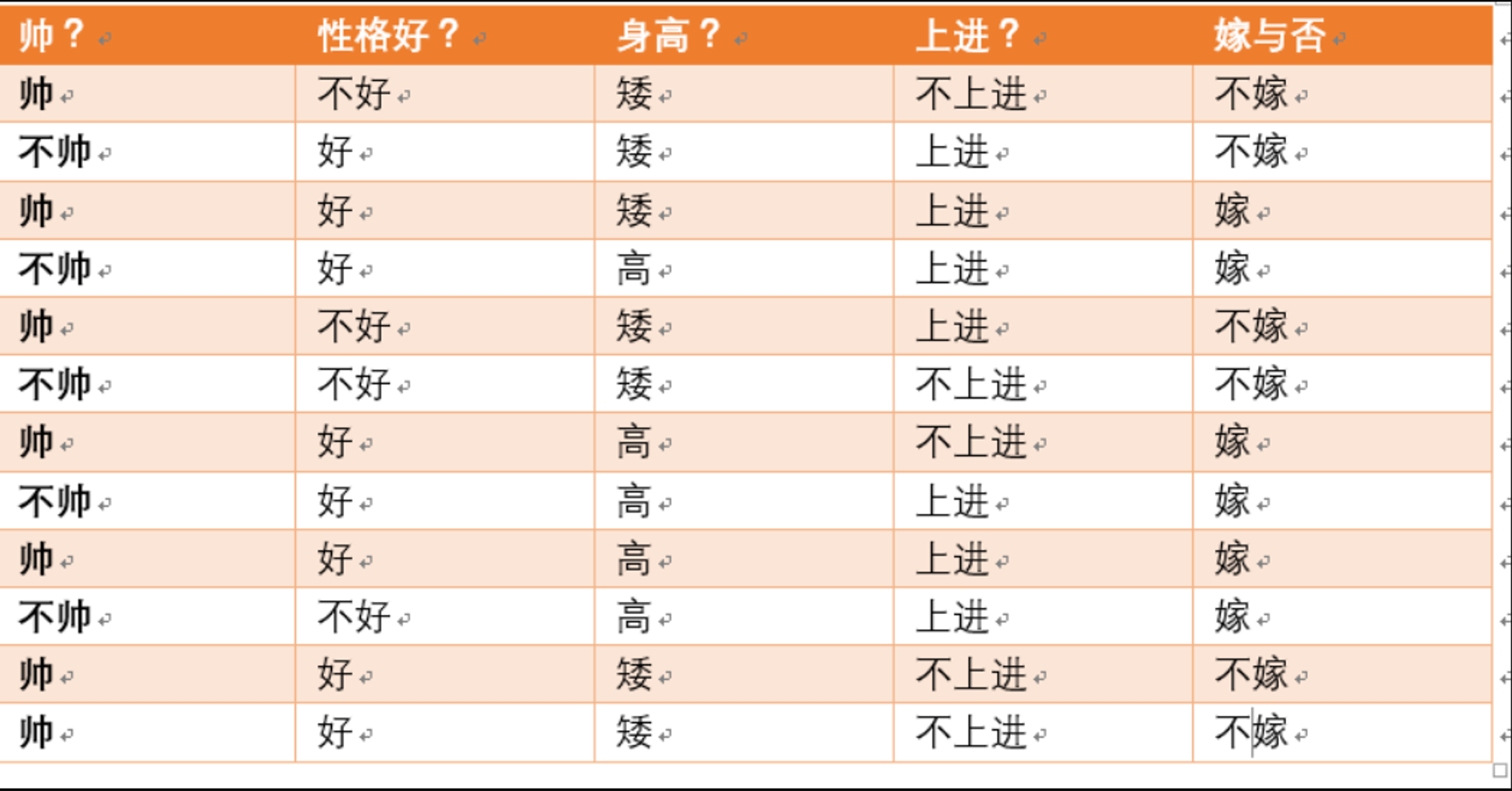
首先,我们用贝叶斯公式将嫁和不嫁的概率都表示出来:
我们先来计算嫁的概率,将嫁的概率表达式换成朴素贝叶斯:
然后我们可以计算出:
的概率为: 1/2

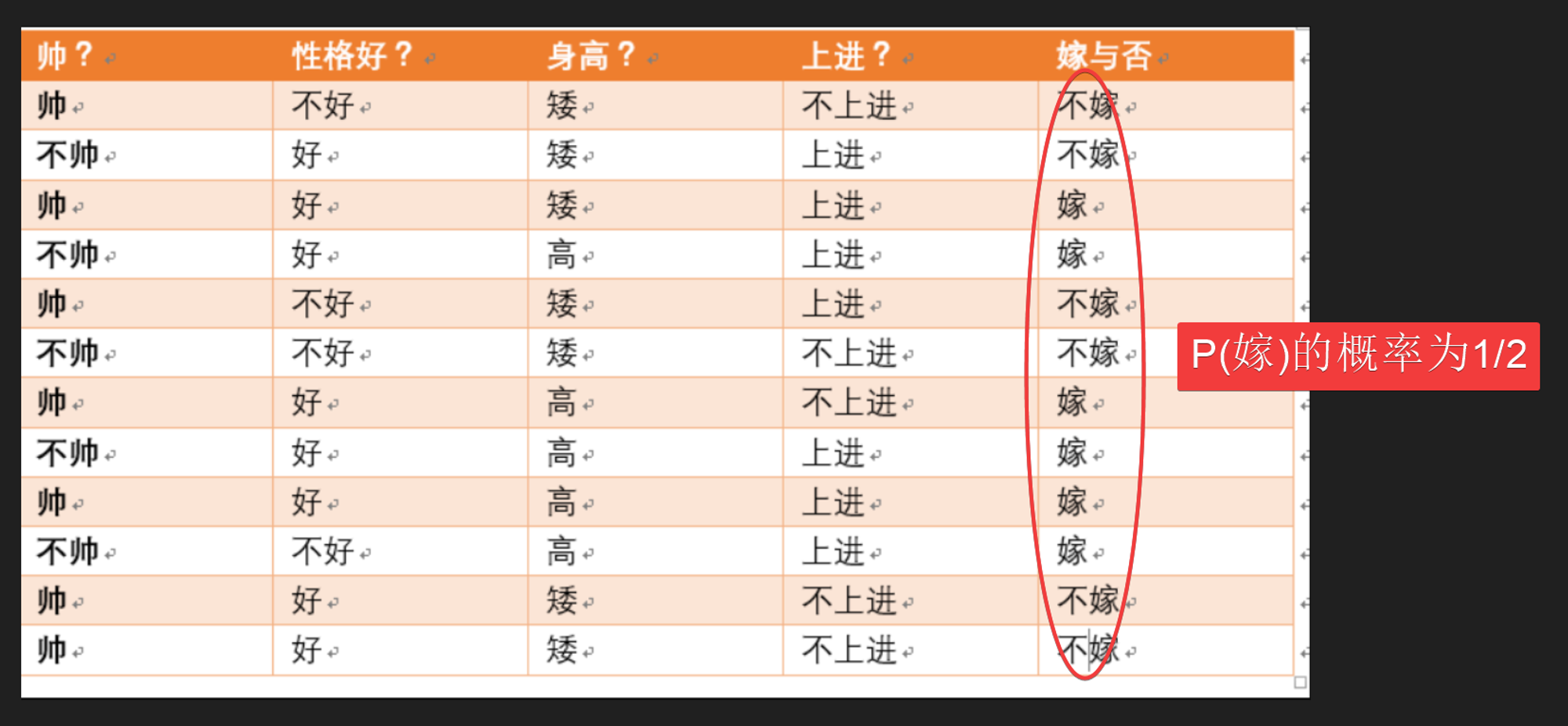
的概率为: 1/2

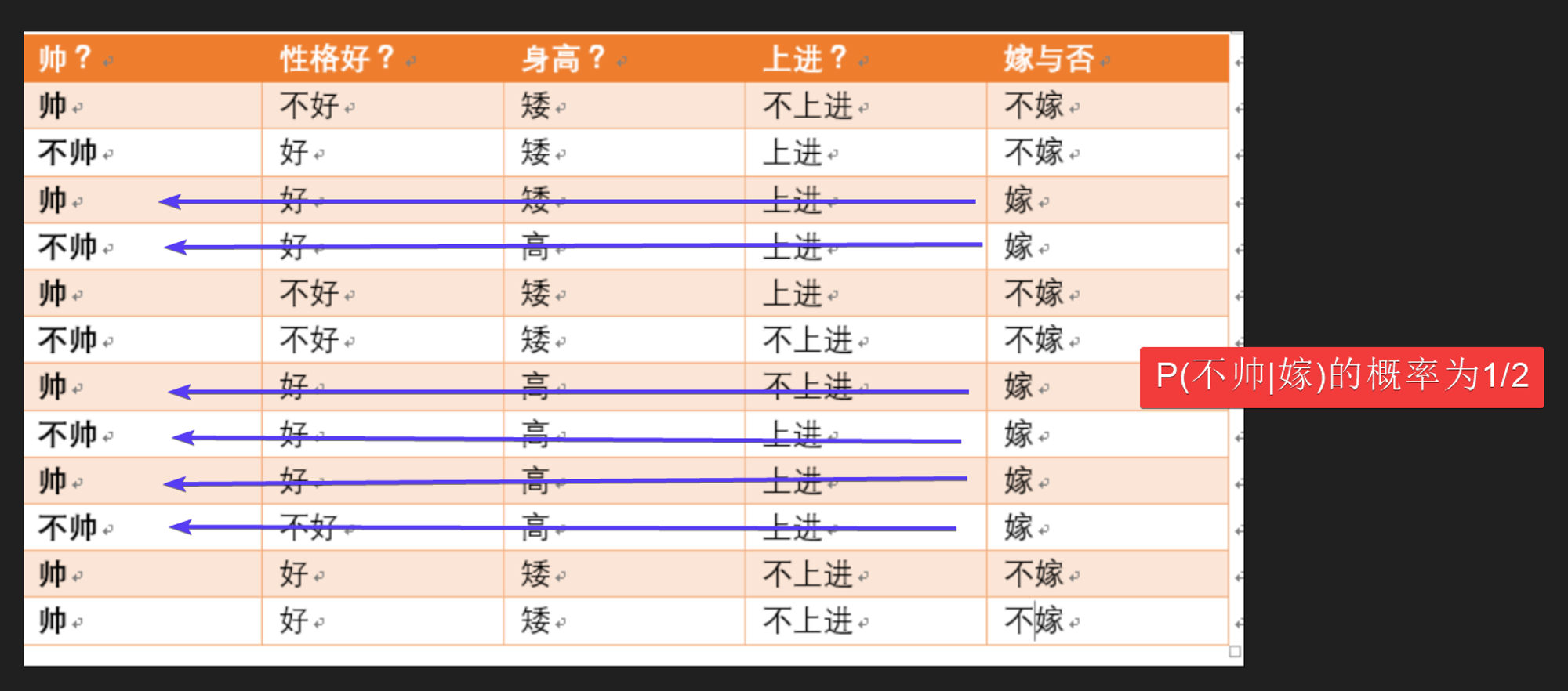
依次类推, 可以计算出的概率,从而计算出这个女孩会嫁给这个男孩的概率;同样的,我们还可以计算出不嫁的概率,在概率大小的比较之后我们就能判断出这个女孩会不会嫁给这个男孩
4、朴素贝叶斯对垃圾邮件进行分类(代码)
# 一、导包获取数据 import warnings warnings.filterwarnings('ignore') import numpy as np import pandas as pd from sklearn.naive_bayes import GaussianNB,BernoulliNB,BaseDiscreteNB,MultinomialNB from sklearn.model_selection import train_test_split sms = pd.read_csv('./SMSSpamCollection.csv', sep='\t', header=None) sms.rename({0:'label', 1:'message'}, axis = 1, inplace=True) # 该表头 display(sms.shape, sms.head()) X = sms[['message']] # 机器学习要求数据是二维的,若只有一个中括号则数据类型的Serios y = sms[['label']] # 二、对邮件文本内容(字符串)进行量化 # feature_extraction特征提取 # CountVectorizer统计词频 # 中文词频统计包: 结巴分词(pip install jieba) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() X_ = cv.fit_transform(sms['message']) # 稀松矩阵 # 返回sparse matrix稀松矩阵,节省内存 # 5572x8713表示5572条短信中提取到8713个词 # cv.vocabulary_ 查看单词在稀松矩阵中的例数 # (0, 3571) 1 表示第一行(第一封邮件)第3571列代表的词有一个 # (0, 8084) 1 表示第一行(第一封邮件)第8084列代表的词有一个 # 以此类推 sparse.save_npz('./sms.npz', X_) # 稀松矩阵只有100KB大小 X = X_.toarray() # 常规矩阵 np.savez('./sms2.npz', X) # 常规矩阵有388MB大小 # sparse.csc_matrix() 方法可以将常规矩阵转换成稀松矩阵 # toarray() 方法可以将稀松矩阵转回正常矩阵 # 三、分数据 # 常规数据 X_train,X_test, y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1187) # 稀松矩阵的数据 X_train_,X_test_, y_train,y_test = train_test_split(X_,y,test_size=0.2,random_state=1187) # 四、用不同的模型进行分类 %%time # 高斯分布 gNB = GaussianNB() # 数据必须是正常矩阵,稀疏矩阵会报错 gNB.fit(X_train, y_train) gNB.score(X_test, y_test) ''' Wall time: 1.51 s 0.8914798206278027 ''' %%time # 伯努利分布 bNB = BernoulliNB() # 数据支持稀松举证(提高运行效率) bNB.fit(X_train_, y_train) bNB.score(X_test_, y_test) ''' Wall time: 20 ms 0.9730941704035875 ''' %%time # 多项式分布 mNB = MultinomialNB() # 数据支持稀松举证(提高运行效率) mNB.fit(X_train_, y_train) mNB.score(X_test_, y_test) ''' Wall time: 20.9 ms 0.979372197309417 '''
贝叶斯的选择
- BernoulliNB(先验为伯努利分布的朴素贝叶斯):如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB
- MultinomialNB(先验为多项式分布的朴素贝叶斯):如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适
- GaussianNB(先验为高斯分布的朴素贝叶斯):如果样本特征的分布大部分是连续值,使用GaussianNB会比较好(如果输入稀疏矩阵会报错,只接受稠密数据)
5、朴素贝叶斯算法小结
朴素贝叶斯的主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下, 假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。