集成学习 | Ensemble Learning
1、集成学习
常见的集成学习框架有三种:
- Bagging
- Boosting
- Stacking
三种集成学习框架在基学习器的产生和综合结果的方式上会有些区别
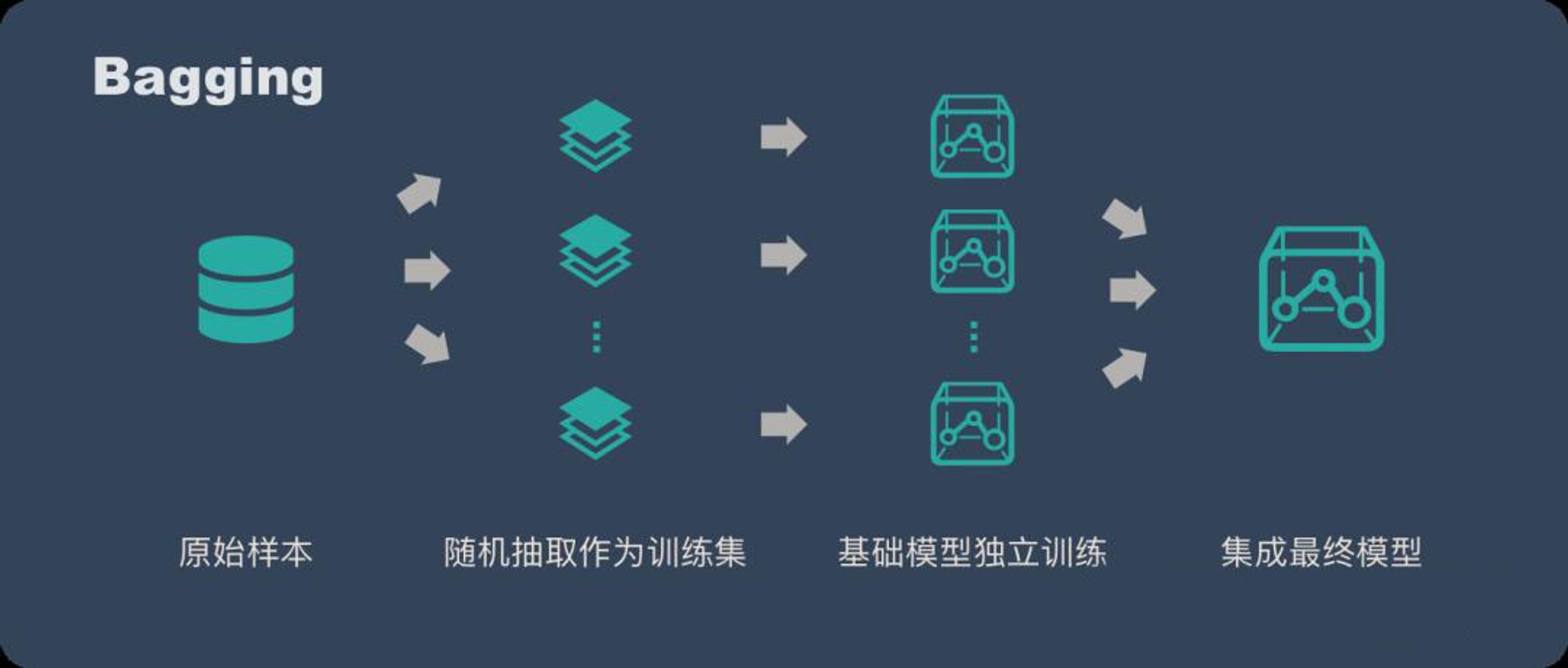
1.1、Bagging
Bagging 全称叫 Bootstrap aggregating,
- 在不同的数据上(同一个数据集进行有返回抽样)使用相同的算法进行训练。
- 综合所有基学习器的预测值得到最终的预测结果。常用的综合方法是投票法(分类)和平均法(回归)

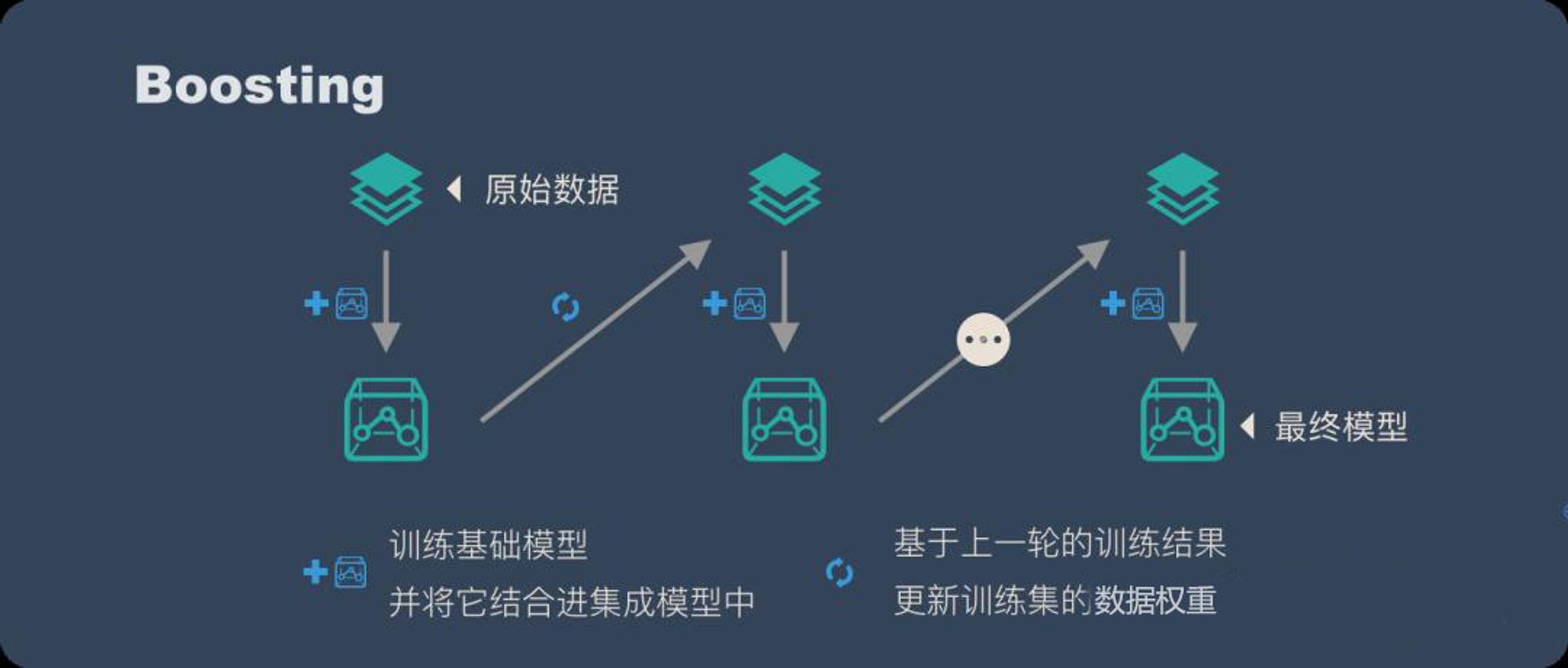
1.2、Boosting
Boosting 训练过程为阶梯状,基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果,用的比较多的综合方式为加权法。
比如任务是预测年龄,那么在训练的时候对其中一个样本他的年龄真实值是30,第一个基学习器预测为25,那么残差为5,第二个基学习器在第一个基学习器的基础上继续进行训练,此时第二个基学习器的预测目标就变成了5,如果它给出的预测值为3,那么下一轮的残差为2,下一个基学习器继续在此基础上进行预测。

1.3、Stacking
Stacking 的思路和 Bagging 类似,只是多个基学习器是不同的算法。此时数据也不用进行采样,使用全量数据集。最终在组合的时候可以使用平局,也可以使用加权平均,加权平均的加权值可以通过训练学习到。




那么,为什么集成学习会好于单个学习器呢?原因可能有三:
- 训练样本可能无法选择出最好的单个学习器,由于没法选择出最好的学习器,所以干脆结合起来一起用;
- 假设能找到最好的学习器,但由于算法运算的限制无法找到最优解,只能找到次优解,采用集成学习可以弥补算法的不足;
- 可能算法无法得到最优解,而集成学习能够得到近似解。比如说最优解是一条对角线,而单个决策树得到的结果只能是平行于坐标轴的,但是集成学习可以去拟合这条对角线。
2、Bagging 和 Boosting 的不同
- 样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
- 样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
- 预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
- 并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
3、偏差与方差
方差是指模型在不同训练集上预测结果的差异程度。高方差意味着模型对训练数据的微小变化非常敏感,导致在不同训练集上训练出的模型差异很大。
偏差是指模型的预测结果与真实值之间的系统性误差。高偏差意味着模型的预测结果与真实值之间存在较大的偏差,通常是由于模型过于简单,无法捕捉数据的复杂模式。


图中的加号表示标准模型的位置,现在从指定数据集中抽取数据训练模型,训练5次,
- 这五个模型如果都落在圆圈内(偏差小),且模型差异较小(方差小)
- 这五个模型如果都落在圆圈外(偏差大),但模型差异较小(方差小)
- 这五个模型如果都落在圆圈内(偏差小),但模型差异较大(方差大)
- 这五个模型如果都落在圆圈外(偏差大),且模型差异较大(方差大)

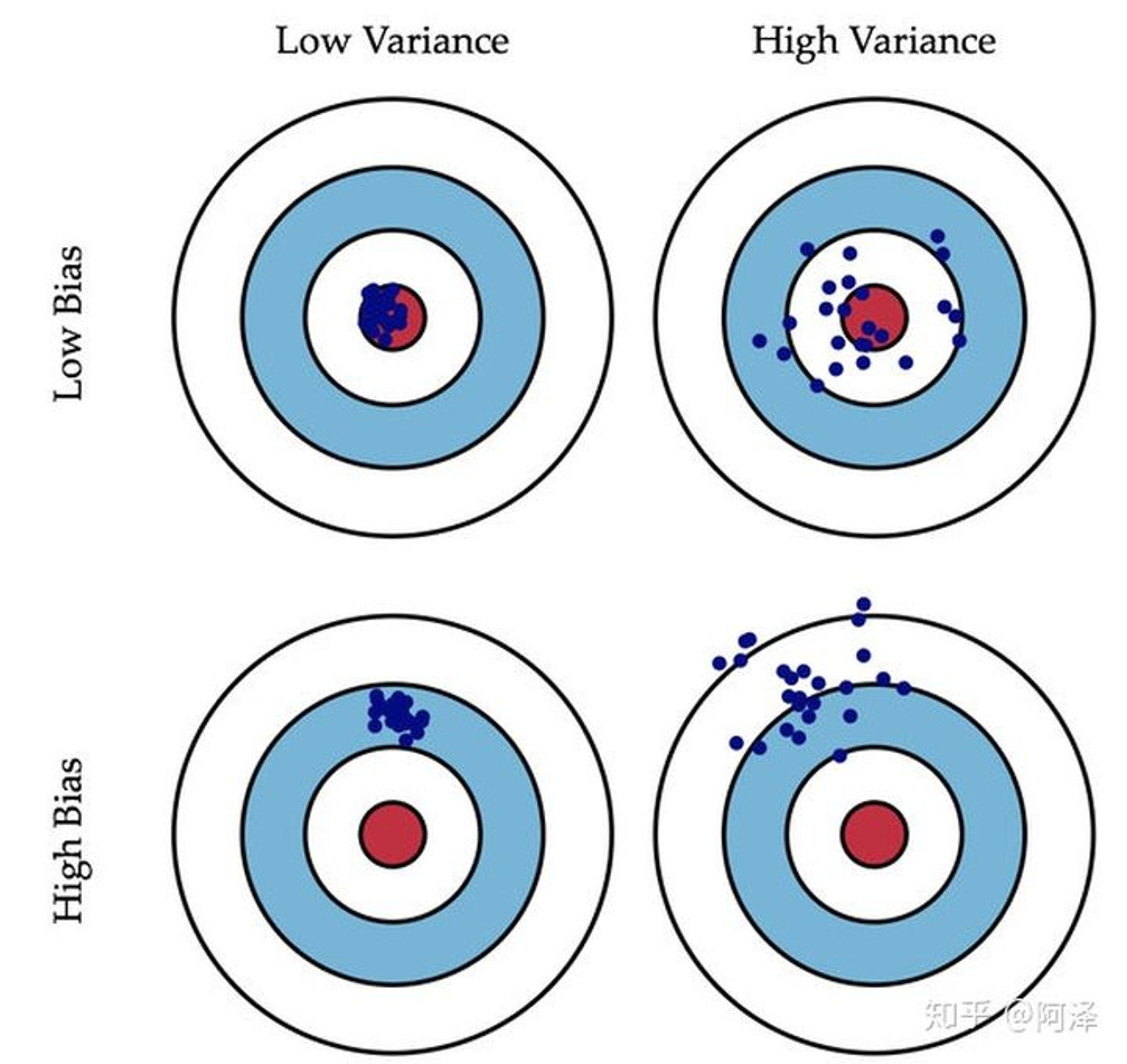
- 偏差:描述样本拟合出的模型的预测结果的期望与样本真实结果的差距,要想偏差表现的好,就需要复杂化模型,增加模型的参数,但这样容易过拟合,过拟合对应上图的 High Variance,点会很分散。低偏差对应的点都打在靶心附近,所以喵的很准,但不一定很稳;
- 方差:描述样本上训练出来的模型在测试集上的表现,要想方差表现的好,需要简化模型,减少模型的复杂度,但这样容易欠拟合,欠拟合对应上图 High Bias,点偏离中心。低方差对应就是点都打的很集中,但不一定是靶心附近,手很稳,但不一定瞄的准。
我们常说集成学习中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型,但并不是所有集成学习框架中的基模型都是弱模型。Bagging 和 Stacking 中的基模型为强模型(偏差低,方差高),而Boosting 中的基模型为弱模型(偏差高,方差低)。
小结
- 我们可以使用模型的偏差和方差来近似描述模型的准确度;
- 对于 Bagging 来说,整体模型的偏差与基模型近似,而随着模型的增加可以降低整体模型的方差,故其基模型需要为强模型;
- 对于 Boosting 来说,整体模型的方差近似等于基模型的方差,而整体模型的偏差由基模型累加而成,故基模型需要为弱模型。