Pytorch速查
type
Post
date
Aug 31, 2023
summary
PyTorch Geometric is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. skorch. skorch is a high-level library for ...
category
学习笔记
tags
pytorch
速查
深度学习
框架
password
URL
Property
Jun 20, 2025 01:47 AM
张量(Tensor)是Pytorch中的基本数据结构
参考文章
创建张量
import torch a = torch.Tensor([3]) # (不推荐)创建一个包含 [3] 的一维张量 a = torch.Tensor(5, 3) # (不推荐)创建一个 5x3 的张量(数值为0) a = torch.Tensor([5, 3]) # (不推荐)创建一个包含 [5, 3] 的一维张量;基于数值序列、NumPy 数组张量,只能创建浮点型张量(默认为 float32),不能指定类型 a = torch.tensor([5, 3]) # 创建一个包含 [5, 3] 的一维张量;接受的输入数据类型更广泛,会根据输入数据推断数据类型,可以通过 dtype 参数明确指定数据类型 a = torch.empty(5, 3) # 创建一个未初始化的5x3张量 a = torch.eye(3, 3) # 创建一个对角为1,其余为0的方形张量 a = torch.arange(1, 4) # 返回值[1,2,3] a = torch.arange(4) # 返回值[0,1,2,3] a = torch.range(1, 4) # 新版本弃用,返回值[1,2,3,4] a = torch.rand(5, 3) # 创建一个5x3张量,值在[0,1)之间均匀分布(Returns a tensor filled with random numbers from a uniform distribution on the interval [0,1)) a = torch.randn(5, 3) # 创建一个5x3张量,值服从正态分布(Returns a tensor filled with random numbers from a normal distribution with mean 0 and variance 1 (also called the standard normal distribution).) b = torch.randn_like(a, dtype=torch.float) # 创建一个形状与a相同的随机数值张量,并且重新定义类型为float a = torch.normal(2, 3, size=(2, 4)) # 创建一个均值为2,标准差为3,形状为2x4的张量 a = torch.randperm(5) # 创建一个一维的张量,值为[0,5)的整数随机排列 a.zero_() # 将原本的张量a用0填充 a = torch.zeros(5, 3, dtype=torch.long) # 创建一个5x3的全0张量,类型为long b = torch.zeros_like(a) # 创建一个形状与a相同的全0张量 a = torch.ones(5, 3, dtype=torch.double) # 创建一个5x3的全1张量(单位张量),类型为double b = torch.ones_like(a) # 创建一个形状与a相同的全1张量 a = torch.full((5,3),4) # 创建一个5x3的、值全为4的张量
rand()、randn()、ones()、zeros()、eye()、full(input,x)、arange()、linspace()、randint(begin,end,n) 以上都可加_like(a),表示生成size和a一样的tensor Pytorch中结尾带下划线_的方法表示就地执行
张量操作
x = torch.randn([1,5,2]) # 索引——张量有多少个维度,切片的时候就可以有多少个参数 x[:,:3] x[:,:3,:1] x[:,:3,:1,:] # 报错 x.dtype # 查看数据类型(torch 一般默认元素时 64 位浮点数,但是深度学习建议使用 32 位浮点数,能加快运算速度) x.type_as(b) # 数据类型转换 x.item() # 从张量中提取元素 x.clone() # 克隆一个张量 x.shape() # 查看一个张量的形状 x.reshape() # 改变一个张量的形状(官方不推荐使用), x.view() # 改变一个张量的形状 # 新张量与原张量的内存共享,如果想要互不影响,先使用clone创建张量副本 # view只能用于内存中连续存储的tensor,如果不连续先调用.contiguous()方法,使tensor的元素在内存空间中连续,然后调用.view() x.expand(3,5,2) # 维度扩展(只能沿着值为1的维度扩展(x的原始维度为1,5,2),扩展的方法就是将该维度内的内容复制一份) x.transpose(0,1) # 维度交换(参数为维度的索引值,只能交换两个维度,x的维度交换之后为5,1,2) x.permute(2,0,1) # 维度交换(参数为维度的索引值,可以交换多个维度,x的维度交换之后为2,1,5) x.t() # 转置 x.T # 转置 torch.squeeze(x, dim=None) # 🚩除去输入张量中数值为1的维度 torch.unsqueeze(x, dim=None) # 🚩在指定位置插入一维 torch.cat((x, x, x), dim=0) # 🚩同维拼接,拼接之后维度不变 torch.stack((x, x, x), dim=0) # 🚩扩维拼接,拼接之后维度提升一维 torch.chunk(x,chunks,dim=0) # 将张量按维度dim进行平均切分,chunks是拆分的份数 torch.split(,split_size_or_sections,dim=0) # 将张量按维度dim进行切分,split_size_or_sections 为 int 时,表示每一份的长度;为 list 时,按 list 元素切分。 torch.equal() # 判断两个张量是否相等 v,s = torch.sort(input,descending=True) # 对一个张量进行排序,返回两个张量;一个是排序后的张量,一个是排序后数值原来的索引 torch.diag(x) # 取x对角线元素形成一个一维向量
张量运算
- 广播规则: 从右到左比较两个张量的每一个维度:
- 如果两个维度相等,或者其中一个为 1,则这两个维度可以匹配。
- 如果维度不同且都不为 1,则不能广播。
- 缺失的维度会被视为 1。
x = torch.randn([1,5,2]) y = torch.arange(24).reshape([2,3,4]).float() # 类型修改 x.short() # 16位整型 x.int() # 32位整型 x.long() # 64位整型 x.float() # 32位浮点型 x.double() # 64位浮点型 # 聚合运算(在指定轴上进行聚合运算🚩) torch.sum(x,dim) # 获取指定维度上的求和(在某个轴上求和,就是将该轴的长度降为 0,如张量形状为[2,5,4],在 axis=1 的轴上求和得到的形状为:[2,4],如果设置参数 keepdims=True,则得到的形状为:[2,1,4]) torch.mean(x,dim) x.sum(dim) x.sum(dim, keepdims=True) # 保持维度不变 x.mean(dim) x.cumsum(axis=0) # 累加求和 # 比较运算 x.max(dim) torch.max(x,dim) # 获取指定维度上的最大值 x.min(dim) torch.min(x,dim) # 获取指定维度上的最小值 x.abs() torch.abs(a) # 绝对值;将张量中的负数用绝对值替换 # 算术元算: # 1. 如果两个张量的形状完全相同,那么逐元素运算会直接进行。 # 2. 如果两个张量的形状不同,但它们可以通过广播机制使得形状匹配,那么运算也可以进行。 x.add_(1) # 如果只有一个数值,则会进行广播 z = x + y torch.add(x,y) # 对应位置相加,要求形状相同,x和y既可以是Tensor也可以是标量 z = x - y torch.sub(x,y) # 对应位置相减,要求形状相同,x和y既可以是Tensor也可以是标量 z = x * y # 哈达马乘积(矩阵对应位置相成) torch.mul(x,y) # 对应位置相乘,要求形状相同,x和y既可以是Tensor也可以是标量 z = x / y torch.div(x,y) # 对应位置相除,要求形状相同,x和y既可以是Tensor也可以是标量 z = 3 * x # 3 乘以 x 中的所有元素(广播) z = 3 + x # 3 加上 x 中的所有元素(广播) # 代数运算 torch.dot(a,b) # 一维向量之间的点积 torch.mv(x,a) # 矩阵与向量相乘,x 必须是矩阵,a 必须是向量 torch.mm(x,y.T) # 二维矩阵之间的叉乘,要求x和y必须是矩阵 torch.matmul(A, B) # 任意维度矩阵乘法,要求第一个矩阵的列数等于第二个矩阵的行数。 # 统计运算 torch.std(x, dim) # 标准差 torch.var(x, dim) # 方差 torch.median(x, dim) # 中位数 # 范数运算(范数是一个向量或矩阵的长度):torch.norm(x) 可以根据 x 的形状和 p 参数的值来计算不同类型的范数 # 1. 向量范数 x = torch.tensor([1.0, -2.0, 3.0]) l1_norm = torch.norm(x, p=1) # L1 范数是张量中所有元素绝对值的和。 l2_norm = torch.norm(x, p=2) # L2 范数是张量中所有元素平方和的平方根,也叫欧几里得范数。norm方法默认p=2 inf_norm = torch.norm(x, p=float('inf')) # 无穷范数是张量中元素绝对值的最大值。 # 2. 矩阵范数 frobenius_norm = torch.norm(x) # Frobenius 范数是矩阵中所有元素平方和的平方根,类似于 L2 范数,但用于矩阵。 spectral_norm = torch.norm(x, p=2) # 计算谱范数 nuclear_norm = torch.norm(x, p=1) # 计算核范数 # 对数、指数、幂函数 torch.log(input, out=None) torch.log10(input, out=None) torch.log2(input, out=None) torch.exp(input, out=None) torch.pow(x,n) # 幂次方,每个元素进行幂次方 torch.clamp(x,m,n) # 对x进行裁剪,如果x中的值大于m,则将该值替换为m;如果x中的值小于n,则将该值替换为n; torch.norm(x, p=2, dim=1) # 计算张量x在维度1上的p范数 # 所有结尾带下划线_符号的函数都会对原数据进行修改
运行设备切换
print(torch.__version__) # pytorch版本 print(torch.version.cuda) # cuda版本 print(torch.cuda.is_available()) # 查看cuda是否可用 dev = torch.device("cuda" if torch.cuda.is_available() else "cpu") # #使用GPU or CPU x = torch.tensor([1,2], device=dev) # 创建指定环境dev中的的tensor x.device # 判断某个对象是在什么环境中运行的 x = x.to(device='cuda') # 将对象环境设置为GPU环境 x = x.to(device='cpu') # 将对象环境设置为CPU环境 x = x.cpu() # 将对象环境设置为CPU环境 x.cpu().numpy() # cuda环境下tensor不能直接转化为numpy类型,必须要先转化到cpu环境中 x+y.to(device=dev) # 若一个没有环境的对象与另外一个有环境x对象进行交流,则环境全变成环境x
数据加载
Pytorch中的数据集
数据集名称 | 数据集类型 | 数据集描述 | 数据集加载方法 | 加载参数 |
MNIST | 图像分类 | 手写数字识别数据集,包含 60,000 张训练图像和 10,000 张测试图像 | torchvision.datasets.MNIST | root, train=True, transform=None, target_transform=None, download=False |
CIFAR-10 | 图像分类 | 10类彩色图像数据集,包含 50,000 张训练图像和 10,000 张测试图像 | torchvision.datasets.CIFAR10 | root, train=True, transform=None, target_transform=None, download=False |
CIFAR-100 | 图像分类 | 100类彩色图像数据集,包含 50,000 张训练图像和 10,000 张测试图像 | torchvision.datasets.CIFAR100 | root, train=True, transform=None, target_transform=None, download=False |
ImageNet | 图像分类 | 1000类大规模图像数据集 | torchvision.datasets.ImageNet | root, split='train', transform=None, target_transform=None |
COCO | 目标检测/分割 | 大规模目标检测、分割和标注数据集 | torchvision.datasets.CocoDetection | root, annFile, transform=None, target_transform=None |
VOC | 目标检测 | Pascal VOC目标检测数据集 | torchvision.datasets.VOCDetection | root, year='2012', image_set='train', download=False, transform=None |
FashionMNIST | 图像分类 | 时尚物品分类数据集,结构同MNIST | torchvision.datasets.FashionMNIST | root, train=True, transform=None, target_transform=None, download=False |
SVHN | 图像分类 | 街景门牌号数字识别数据集 | torchvision.datasets.SVHN | root, split='train', transform=None, target_transform=None, download=False |
STL10 | 图像分类 | 适用于无监督学习的图像数据集 | torchvision.datasets.STL10 | root, split='train', transform=None, target_transform=None, download=False |
CelebA | 人脸属性 | 大规模人脸属性数据集 | torchvision.datasets.CelebA | root, split='train', transform=None, target_transform=None, download=False |
LSUN | 场景理解 | 大规模场景理解数据集 | torchvision.datasets.LSUN | root, classes='train', transform=None, target_transform=None |
Cityscapes | 语义分割 | 城市街景语义分割数据集 | torchvision.datasets.Cityscapes | root, split='train', mode='fine', target_type='instance', transform=None |
SBU | 图像描述 | 图像描述数据集 | torchvision.datasets.SBU | root, transform=None, target_transform=None, download=False |
Flickr | 图像描述 | Flickr图像描述数据集 | torchvision.datasets.Flickr8k/30k | root, ann_file, transform=None, target_transform=None |
PhotoTour | 图像匹配 | 照片特征匹配数据集 | torchvision.datasets.PhotoTour | root, name, transform=None, download=False |
Omniglot | 少样本学习 | ㅤ | torchvision.datasets.Omniglot | root, background=True, transform |
Kinetics400 | 视频分类 | ㅤ | torchvision.datasets.Kinetics400 | root, frames_per_clip, transform |
UCF101 | 视频分类 | ㅤ | torchvision.datasets.UCF101 | root, annotation_path, frames_per_clip |
HMDB51 | 视频分类 | ㅤ | torchvision.datasets.HMDB51 | root, annotation_path, frames_per_clip |
一个简单的数据加载例子
# 构建数据集:可以理解为对数据进行摸底并记录相关信息 class ToyDataset(Dataset): def __init__(self,X,Y): self.X = X self.Y = Y def __len__(self): return len(self.X) # 1、获取数据集长度 def __getitem__(self,index): # 参数 index 是由 DataLoader 内部在迭代时提供的 return self.X[index],self.Y[index] # 3、根据索引提取数据,索引参数来自每次数据加载器产生的数据索引 X,Y = torch.randn(1000,3),torch.randint(low=0,high=2,size=(1000,)).float() ds = ToyDataset(X,Y) # 数据加载器:指定批次、 dl = DataLoader(ds,batch_size=4,drop_last = False) # 2、指定批次大小 features,labels = next(iter(dl)) # 在数据加载器的迭代过程中,每次迭代会调用数据集类的 __getitem__ 方法,传递一个索引值作为参数,以获取对应索引的样本 # 在每个批次中,DataLoader 会自动计算批次中每个样本在数据集中的索引,然后调用数据集类的 __getitem__ 方法,将这些索引作为参数传递给它。 print("features = ",features ) print("labels = ",labels )
创建数据集TensorDataset、Dataset
创建自定义数据集
from pathlib import Path from PIL import Image class Cifar2Dataset(Dataset): def __init__(self,imgs_dir,img_transform): self.files = list(Path(imgs_dir).rglob("*.jpg")) self.transform = img_transform def __len__(self,): return len(self.files) def __getitem__(self,i): file_i = str(self.files[i]) img = Image.open(file_i) tensor = self.transform(img) label = torch.tensor([1.0]) if "1_automobile" in file_i else torch.tensor([0.0]) return tensor,label train_dir = "./eat_pytorch_datasets/cifar2/train/" test_dir = "./eat_pytorch_datasets/cifar2/test/" # 定义图片增强 transform_train = transforms.Compose([ transforms.RandomHorizontalFlip(), #随机水平翻转 transforms.RandomVerticalFlip(), #随机垂直翻转 transforms.RandomRotation(45), #随机在45度角度内旋转 transforms.ToTensor() #转换成张量 ] ) transform_val = transforms.Compose([ transforms.ToTensor() ] ) ds_train = Cifar2Dataset(train_dir,transform_train) ds_val = Cifar2Dataset(test_dir,transform_val) dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True) dl_val = DataLoader(ds_val,batch_size = 50,shuffle = True) for features,labels in dl_train: print(features.shape) print(labels.shape) break
根据Tensor创建数据集
import numpy as np import torch from torch.utils.data import TensorDataset,Dataset,DataLoader,random_split # 根据Tensor创建数据集 from sklearn import datasets iris = datasets.load_iris() ds_iris = TensorDataset(torch.tensor(iris.data),torch.tensor(iris.target)) # 分割成训练集和预测集 n_train = int(len(ds_iris)*0.8) n_val = len(ds_iris) - n_train ds_train,ds_val = random_split(ds_iris,[n_train,n_val]) print(type(ds_iris)) print(type(ds_train)) # 使用DataLoader加载数据集 dl_train,dl_val = DataLoader(ds_train,batch_size = 8),DataLoader(ds_val,batch_size = 8) for features,labels in dl_train: print(features,labels) break # 演示加法运算符(`+`)的合并作用 ds_data = ds_train + ds_val print('len(ds_train) = ',len(ds_train)) print('len(ds_valid) = ',len(ds_val)) print('len(ds_train+ds_valid) = ',len(ds_data)) print(type(ds_data))
根据图片目录创建图片数据集
import numpy as np import torch from torch.utils.data import DataLoader from torchvision import transforms,datasets # 根据图片目录创建数据集 def transform_label(x): return torch.tensor([x]).float() ds_train = datasets.ImageFolder("./eat_pytorch_datasets/cifar2/train/", transform = transform_train,target_transform= transform_label) ds_val = datasets.ImageFolder("./eat_pytorch_datasets/cifar2/test/", transform = transform_valid, target_transform= transform_label) print(ds_train.class_to_idx) # 使用DataLoader加载数据集 dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True) dl_val = DataLoader(ds_val,batch_size = 50,shuffle = True) for features,labels in dl_train: print(features.shape) print(labels.shape) break
加载数据集DataLoader
DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据
dataset 可以直接给 dataframe
DataLoader( dataset, # 数据集 batch_size=1, # 批次大小 shuffle=False, # 是否乱序 sampler=None, # 样本采样函数,一般无需设置。 batch_sampler=None, # 批次采样函数,一般无需设置。 num_workers=0, # 使用多进程读取数据,设置的进程数。mac电脑设置会报错 collate_fn=None, # 整理一个批次数据的函数。 pin_memory=False, # 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存(硬盘),从锁业内存拷贝到GPU上速度会更快。 drop_last=False, # 是否丢弃最后一个样本数量不足batch_size批次数据。 timeout=0, # 加载一个数据批次的最长等待时间,一般无需设置。 worker_init_fn=None, # 每个worker中dataset的初始化函数,常用于 IterableDataset。一般不使用。 multiprocessing_context=None, )
一般情况下,我们仅仅会配置 dataset, batch_size, shuffle, num_workers,pin_memory, drop_last这六个参数
其他方法
torch.utils.data.random_split # 将一个数据集分割成多份,常用于分割训练集,验证集和测试集。
数据预处理
这些数据处理方法的选择要根据具体任务和数据特点来决定:
- 图像任务通常需要更多的数据增强
- NLP任务可能需要更多的文本预处理
- 结构化数据可能需要更多的特征工程
- 时序数据可能需要特殊的采样策略
图像
# 裁剪——Crop transforms.CenterCrop() # 中心裁剪 transforms.RandomCrop() # 随机裁剪 transforms.RandomResizedCrop() # 随机长宽比裁剪 transforms.FiveCrop() # 上下左右中心裁剪 transforms.TenCrop() # 上下左右中心裁剪后翻转 # 翻转和旋转——Flip and Rotation transforms.RandomHorizontalFlip(p=0.5)() # 依概率p水平翻转 transforms.RandomVerticalFlip(p=0.5)() # 依概率p垂直翻转 transforms.RandomRotation() # 随机旋转 # 图像变换 transforms.Resize() # resize transforms.Normalize() # 标准化 transforms.ToTensor() # 转为tensor,并归一化至[0-1] transforms.Pad() # 填充 transforms.ColorJitter() # 修改亮度、对比度和饱和度 transforms.Grayscale() # 转灰度图 transforms.LinearTransformation()() # 线性变换 transforms.RandomAffine() # 仿射变换 transforms.RandomGrayscale() # 依概率p转为灰度图 transforms.ToPILImage() # 将数据转换为PILImage # 对transforms操作,使数据增强更灵活 transforms.RandomChoice(transforms) # 从给定的一系列transforms中选一个进行操作 transforms.RandomApply(transforms, p=0.5) # 给一个transform加上概率,依概率进行操作 transforms.RandomOrder() # 将transforms中的操作随机打乱
实例
- 数据预处理 :
# 标准化/归一化 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 缩放到指定范围 transforms.Lambda(lambda x: x / 255.0) # 缩放到[0,1] transforms.Lambda(lambda x: (x - 0.5) * 2) # 缩放到[-1,1] # 数据类型转换 torch.FloatTensor(data) torch.LongTensor(labels)
- 数据增强 :
# 图像增强示例 transforms.Compose([ transforms.RandomHorizontalFlip(p=0.5), # 水平翻转 transforms.RandomRotation(10), # 随机旋转 transforms.RandomResizedCrop(224), # 随机裁剪并缩放 transforms.ColorJitter(brightness=0.4), # 亮度调整 transforms.RandomAffine(degrees=0, translate=(0.1,0.1)), # 仿射变换 transforms.RandomErasing(p=0.5) # 随机擦除 ]) # 文本增强示例 def text_augment(text): # 同义词替换 # 回译 # 随机删除 # 随机插入 pass
- 数据清洗 :
# 异常值处理 def remove_outliers(data, threshold=3): z_scores = np.abs(stats.zscore(data)) return data[z_scores < threshold] # 缺失值处理 def handle_missing(data): # 删除缺失值 data_cleaned = data.dropna() # 填充缺失值 data_filled = data.fillna(data.mean()) return data_cleaned, data_filled
- 数据采样 :
# 处理类别不平衡 from torch.utils.data import WeightedRandomSampler # 计算采样权重 weights = 1. / torch.tensor(class_counts) samples_weights = weights[targets] # 创建采样器 sampler = WeightedRandomSampler( weights=samples_weights, num_samples=len(samples_weights), replacement=True )
- 数据加载 :
# 自定义数据集 class CustomDataset(Dataset): def __init__(self, data_path, transform=None): self.data = ... self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = self.data[idx] if self.transform: sample = self.transform(sample) return sample # 数据加载器 train_loader = DataLoader( dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True )
- 特征工程 :
# 特征选择 from sklearn.feature_selection import SelectKBest, f_classif # 特征缩放 from sklearn.preprocessing import StandardScaler, MinMaxScaler # 特征编码 from sklearn.preprocessing import LabelEncoder, OneHotEncoder
- 数据集划分 :
# 训练集、验证集、测试集划分 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y # 保持类别比例 )
- 数据流水线 :
class DataPipeline: def __init__(self): self.transforms = [] def add_transform(self, transform): self.transforms.append(transform) def process(self, data): for t in self.transforms: data = t(data) return data
#演示一些常用的图片增强操作 from PIL import Image img = Image.open('./data/cat.jpeg') img # 随机数值翻转 transforms.RandomVerticalFlip()(img) #随机旋转 transforms.RandomRotation(45)(img) # 定义图片增强操作 transform_train = transforms.Compose([ transforms.RandomHorizontalFlip(), #随机水平翻转 transforms.RandomVerticalFlip(), #随机垂直翻转 transforms.RandomRotation(45), #随机在45度角度内旋转 transforms.ToTensor() #转换成张量 ] ) transform_valid = transforms.Compose([ transforms.ToTensor() ] )
torch.nn
# 参考:https://yey.world/2020/12/16/Pytorch-12/ ### 二维卷积层 nn.Conv2d( in_channels, # 输入通道数 out_channels, # 输出通道数,等价于卷积核个数 kernel_size, # 卷积核尺寸 stride=1, # 卷积核移动步长 padding=0, # 填充个数,常用于保持输入输出图像尺寸匹配 dilation=1, # 空洞卷积大小;常用于图像分割任务,目的是提高感受野,即输出图像的一个像素对应输入图像上更大的一块区域 groups=1, # 分组卷积的组数。常用于模型的轻量化。 bias=True, # 偏置。最终输出响应值时需加上偏置项。 padding_mode='zeros' ) # 参考:https://yey.world/2020/12/16/Pytorch-13/ ### 最大池化层 nn.MaxPool2d( kernel_size, # 池化核尺寸 stride=None, # 池化核移动步长 padding=0, # 填充个数 dilation=1, # 池化核间隔大小 return_indices=False, # 记录池化像素索引。通常在最大值反池化上采样时使用。 ceil_mode=False # 尺寸是否向上取整。用于计算输出特征图尺寸,默认设置为向下取整。 ) ### 平均池化层 nn.AvgPool2d( kernel_size, # 池化核尺寸 stride=None, # 池化核移动步长 padding=0, # 填充个数 ceil_mode=False, # 尺寸是否向上取整。用于计算输出特征图尺寸,默认设置为向下取整。 count_include_pad=True, # 是否将填充值用于平均值的计算。 divisor_override=None # 除法因子。计算平均值时代替像素个数作为分母。 ) ### 全连接层(线性层) nn.Linear( in_features, # 输入结点数。 out_features, # 输出结点数。 bias=True # 是否需要偏置。 ) ### 激活函数层 nn.Sigmoid() nn.tanh() nn.ReLU() nn.LeakyReLU() nn.PReLU() nn.RReLU() ### 初始化,参考:https://pytorch.org/docs/stable/nn.init.html#torch-nn-init nn.init.xavier_uniform_(self.conv1.weight) # 均匀分布初始化 nn.init.xavier_normal_(conv_layer.weight.data) # 正态分布初始化
损失函数
torch中常见的损失函数
损失函数调用方法 | 名称 | 适用场景 | 示例 |
nn.MSELoss() | 均方误差损失 | 回归问题,预测连续值 | loss = nn.MSELoss()(pred, target) |
nn.L1Loss() | 平均绝对误差损失 | 回归问题,对异常值不敏感 | loss = nn.L1Loss()(pred, target) |
nn.CrossEntropyLoss() | 交叉熵损失 | 多分类问题 | loss = nn.CrossEntropyLoss()(logits, labels) |
nn.BCELoss() | 二元交叉熵损失 | 二分类问题(需要先sigmoid) | loss = nn.BCELoss()(sigmoid(pred), target) |
nn.BCEWithLogitsLoss() | 带Logits的二元交叉熵损失 | 二分类问题(内置sigmoid) | loss = nn.BCEWithLogitsLoss()(pred, target) |
nn.NLLLoss() | 负对数似然损失 | 多分类问题(需要先log_softmax) | loss = nn.NLLLoss()(log_softmax(pred), target) |
nn.KLDivLoss() | KL散度损失 | 概率分布的相似度度量 | loss = nn.KLDivLoss()(pred_dist.log(), target_dist) |
nn.HuberLoss() | Huber损失 | 回归问题,结合MSE和L1的优点 | loss = nn.HuberLoss(delta=1.0)(pred, target) |
nn.SmoothL1Loss() | 平滑L1损失 | 回归问题,对异常值较为鲁棒 | loss = nn.SmoothL1Loss()(pred, target) |
nn.CosineEmbeddingLoss() | 余弦嵌入损失 | 度量两个向量的相似度 | loss = nn.CosineEmbeddingLoss()(input1, input2, target) |
nn.CTCLoss() | CTC损失 | 序列学习(如语音识别) | loss = nn.CTCLoss()(log_probs, targets, input_lengths, target_lengths) |
nn.MarginRankingLoss() | 边界排序损失 | 排序和排名问题 | loss = nn.MarginRankingLoss()(input1, input2, target) |
nn.MultiMarginLoss() | 多类别边界损失 | 多分类问题的边界优化 | loss = nn.MultiMarginLoss()(pred, target) |
nn.TripletMarginLoss() | 三元组边界损失 | 度量学习,如人脸识别 | loss = nn.TripletMarginLoss()(anchor, positive, negative) |
nn.PoissonNLLLoss() | 泊松负对数似然损失 | 计数数据的回归 | loss = nn.PoissonNLLLoss()(pred, target) |
损失函数的常用参数
损失函数 | 重要参数 | 参数说明 |
CrossEntropyLoss | weight | 各类别的权重,用于处理类别不平衡 |
ㅤ | ignore_index | 忽略特定的标签值,常用于序列任务 |
ㅤ | reduction | 可选'none'/'mean'/'sum',控制损失的归约方式 |
BCELoss | weight | 各样本的权重 |
ㅤ | reduction | 可选'none'/'mean'/'sum',控制损失的归约方式 |
MSELoss | reduction | 可选'none'/'mean'/'sum',控制损失的归约方式 |
常见的损失函数组合使用场景
组合方式 | 使用场景 | 示例 |
MSE + L1 | 图像重建任务 | loss = mse_loss + 0.1 * l1_loss |
CE + KL | 知识蒸馏 | loss = ce_loss + temperature * kl_loss |
Focal Loss | 目标检测中解决正负样本不平衡 | 基于CE的变体 |
一些实用建议
- 对于回归问题:
- 如果数据中有异常值,优先考虑 L1Loss 或 SmoothL1Loss
- 如果数据分布较正常,可以使用 MSELoss
- 对于分类问题:
- 二分类问题推荐使用 BCEWithLogitsLoss(而不是 BCELoss)
- 多分类问题推荐使用 CrossEntropyLoss(而不是手动组合 Softmax + NLLLoss)
- 对于特殊任务:
- 生成模型可能需要组合多个损失函数
- 对抗训练中的损失函数需要分别针对生成器和判别器
优化器:torch.optim
torch中常见的优化算法
优化器调用方法 | 名称 | 适用场景 | 示例 |
torch.optim.SGD | 随机梯度下降 | 最基础的优化器,适用于大多数简单场景 | optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) |
torch.optim.Adam | Adam优化器 | 深度学习最常用的优化器,适用于大多数场景 | optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999)) |
torch.optim.AdamW | AdamW优化器 | 解决Adam中权重衰减实现问题的改进版本 | optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01) |
torch.optim.RMSprop | RMSprop优化器 | 适用于RNN等循环神经网络 | optimizer = optim.RMSprop(model.parameters(), lr=0.01, alpha=0.99) |
torch.optim.Adagrad | Adagrad优化器 | 适用于稀疏数据场景 | optimizer = optim.Adagrad(model.parameters(), lr=0.01) |
torch.optim.Adadelta | Adadelta优化器 | 不需要设置初始学习率,适用于对超参数敏感的模型 | optimizer = optim.Adadelta(model.parameters(), rho=0.9) |
torch.optim.Adamax | Adamax优化器 | Adam的一个变体,对学习率上限提供了更好的控制 | optimizer = optim.Adamax(model.parameters(), lr=0.002) |
torch.optim.ASGD | ASGD优化器 | 随机平均梯度下降,适用于大规模凸优化问题 | optimizer = optim.ASGD(model.parameters(), lr=0.01) |
torch.optim.LBFGS | L-BFGS优化器 | 适用于小批量数据的全批量优化 | optimizer = optim.LBFGS(model.parameters(), lr=1) |
torch.optim.SparseAdam | 稀疏Adam优化器 | 适用于稀疏梯度更新的场景 | optimizer = optim.SparseAdam(model.parameters(), lr=0.001) |
torch.optim.RAdam | 修正Adam优化器 | 解决Adam预热期的问题,训练更稳定 | optimizer = optim.RAdam(model.parameters(), lr=0.001) |
优化器的常用参数
参数 | 说明 | 适用优化器 |
lr | 学习率 | 所有优化器 |
weight_decay | 权重衰减系数 | 所有优化器 |
momentum | 动量系数 | SGD |
betas | 一阶和二阶矩估计的指数衰减率 | Adam系列 |
eps | 数值稳定性系数 | 大多数优化器 |
学习率调度器
调度器 | 说明 | 示例 |
StepLR | 按固定步长降低学习率 | scheduler = StepLR(optimizer, step_size=30, gamma=0.1) |
MultiStepLR | 在指定步数降低学习率 | scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1) |
ExponentialLR | 指数衰减学习率 | scheduler = ExponentialLR(optimizer, gamma=0.95) |
CosineAnnealingLR | 余弦退火调整学习率 | scheduler = CosineAnnealingLR(optimizer, T_max=100) |
ReduceLROnPlateau | 当指标停止改善时降低学习率 | scheduler = ReduceLROnPlateau(optimizer, mode='min', patience=10) |
OneCycleLR | 一个周期的学习率调整 | scheduler = OneCycleLR(optimizer, max_lr=0.1, epochs=10, steps_per_epoch=100) |
优化器的选择建议
- 初始选择 :
- 一般项目首选 Adam
- 需要更好泛化性能时考虑 AdamW
- 计算资源受限时可以使用 SGD+Momentum
- 特殊场景 :
- 图像分类:SGD+Momentum 通常效果更好
- NLP任务:Adam/AdamW 是主流选择
- 生成模型:Adam 及其变体较为常用
常见问题解决方案
- 训练不稳定:降低学习率或使用梯度裁剪
- 收敛太慢:增加学习率或使用自适应优化器
- 过拟合:增加权重衰减或使用学习率调度
- 欠拟合:增加学习率或减少权重衰减
使用示例
import torch import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 定义优化器 optimizer.zero_grad() # 优化器清零 optimizer.step() # 优化器更新参数 # 增加参数 w2 = torch.randn((3, 3), requires_grad=True) optimizer.add_param_group({"params": w2, 'lr': 0.0001}) # 保存优化器状态信息 opt_state_dict = optimizer.state_dict() torch.save(opt_state_dict, os.path.join(BASE_DIR, "optimizer_state_dict.pkl")) # 读取优化器状态信息 state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl")) optimizer.load_state_dict(state_dict) # 梯度裁剪 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 梯度累积 for i in range(accumulation_steps): loss = criterion(model(data), target) loss = loss / accumulation_steps loss.backward() if (i + 1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad() # 不同层使用不同学习率 optimizer = torch.optim.Adam([ {'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3} ], lr=1e-4)
保存和加载模型
PyTorch | 保存和加载模型(包含在训练器的模型保存和加载可以看这里)
多卡分布式训练
分类
- 根据并行策略的不同分为模型并行和数据并行
- 模型并行:模型并行主要应用于模型相比显存来说更大,一块 GPU 无法加载的场景,通过把模型切割为几个部分,分别加载到不同的 GPU 上,来进行训练
- 数据并行:这个是日常会应用的比较多的情况。即每个 GPU 复制一份模型,将一批样本分为多份分发到各个GPU模型并行计算。因为求导以及加和都是线性的,数据并行在数学上也有效。采用数据并行相当于加大了batch_size,得到更准确的梯度或者加速训练。
PyTorch 常用的分布式训练的方式:torch.nn.DataParallel(DP)、torch.nn.DistributedDataParallel(DDP)
多卡训练要考虑通信开销的,是个trade off的过程,不见得四块卡一定比两块卡快多少,可能是训练到四块卡的时候通信开销已经占了大头
- DP 与 DDP 的区别
- 优缺点:
- DP 仅支持单机多卡模式,API 简单,使用起来更友好
- DDP 支持单机多卡、多机多卡模式,训练速度更快,而且负载相对要均衡一些
- 运行方式:
- DP 是通过单进程控制多线程来实现的。
- DDP 通过多进程实现的。为每个GPU创建一个进程进行独立的训练且只对梯度等少量数据进行信息交换。避免了Python解释器GIL带来的性能开销。
- 数据加载:
- DP 只有一个进程,主 GPU 负责加载整个 batch 的数据,然后将数据分散到其他 GPU,所以设置的 batch_size 必须是 GPU 数量的整数倍
- DDP 每个 GPU 对应一个独立进程,每个进程独立加载数据,设置的 batch_size 就是单个 GPU 上的大小;实际的总 batch_size = 单个 GPU 的 batch_size × GPU 数量
DataParallel
DataParallel虽然只是多进程处理,效率不高,但是如果有特殊需求时可以使用。
比如我现在有 4 张 GPU,要根据输入的表来合成数据(涉及深度学习训练、预测),主程序中串行处理多张表(防止资源争夺),需要对表的处理进行超时控制(如果处理超时就停止,处理下一张表),同时每张表的处理都要分布式训练;
由于需要进行超时控制,所以需要为每张表单独开一个子进程(虽然开子进程,但还是需要串行处理),当超时的时候可以通过 kill 掉子进程来停止处理,再开启一个新的子进程来处理下一张表。如果此时使用 DDP 来进行分布式训练,那么在子进程中 DDP 还会开启多个子进程,就会导致进程嵌套,这是会有三层进程,这样就导致进程管理复杂,并且超时控制不一定能控制到 DDP 的子进程。
所以此时应该使用 DP 才能满足场景需求,DP 不会创建新的子进程,进程依旧是两层。牺牲了性能满足了需求。
DistributedDataParallel
DistributedDataParallel是基于 distributed 构建的数据并行训练工具,自动处理梯度同步和参数更新;
- distributed 提供基础通信功能,更灵活但需要手动管理
- DDP 提供便捷的数据并行训练接口,但功能相对固定
DDP 分布式训练步骤:
- 初始化进程组 :使用
dist.init_process_group(backend, init_method, world_size, rank, timeout)初始化分布式环境。
参数 | 含义 | 参数值 | 说明 |
backend | 后端 | 'nccl':NVIDIA GPU 训练的最佳选择
'gloo':CPU 训练的常用选择
'mpi’:需要单独安装,特定场景使用
默认值:None | ㅤ |
init_method | 初始化方法 | TCP: tcp://IP:PORT
文件: file:///path/to/file
环境变量(默认): env:// | 如果使用环境变量方式,需要设置:
- MASTER_ADDR:主节点地址
- MASTER_PORT:主节点端口 |
world_size | 总进程数 | 默认值:从环境变量 WORLD_SIZE 获取 | 大小为:机器数量 ✖️ 每条机器的 GPU 数量 |
rank | 进程序号 | 默认值:从环境变量 RANK 获取 | 范围:0 到 world_size-1
rank=0 通常作为主进程 |
timeout | 进程间通信的超时时间 | 默认值:30分钟 | 单位:秒 |
4台机器(每台机器8张卡)进行分布式训练
参数 | 含义 | 示例 | 获取方法 |
group | 将进程划分为不同的子组,限定集体通信操作只在特定组内进行,限定集体通信操作只在特定组内进行,如模型并行、流水线并行等 | dist.all_reduce(tensor) # 使用默认组
group = dist.new_group(ranks=[0, 1, 2, 3]) | ㅤ |
world_size | 整个分布式训练中的总进程数,等于所有机器上的 GPU 总数 | 32 | torch.distributed.get_world_size() |
rank | 全局进程标识符,在整个分布式系统中唯一标识每个进程 | - 机器1:rank 0-7
- 机器2:rank 8-15
- 机器3:rank 16-23
- 机器4:rank 24-31 | torch.distributed.get_rank()
|
local_rank | 本地机器内的进程标识符,用于确定进程在本地机器上使用哪张 GPU | 0-7 | torch.distributed.local_rank() |
- 模型分布式包装 :使用 DistributedDataParallel 包装模型,使其支持分布式训练。
- 数据分发 :使用 DistributedSampler 确保每个进程获取不同的数据批次。
- 多进程启动 :使用 mp.spawn() 启动多个训练进程。
DDP 加载数据步骤:
- Dataset:创建了数据集的索引,而不是加载所有数据
- DistributedSampler:负责划分数据的索引,将索引分配给不同进程
- DataLoader:实际数据加载
DDP 示例代码:
import torch import torch.distributed as dist import torch.multiprocessing as mp from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data.distributed import DistributedSampler from torch.utils.data import DataLoader def setup(rank, world_size): # 初始化进程组 dist.init_process_group( backend='nccl', # 使用NCCL后端 init_method='tcp://localhost:12355', world_size=world_size, rank=rank ) def cleanup(): dist.destroy_process_group() def train(rank, world_size): # 设置进程组 setup(rank, world_size) # 创建模型 model = YourModel().to(rank) # 将模型包装成DDP模型 model = DDP(model, device_ids=[rank]) # 创建数据集 train_dataset = YourDataset() # 创建分布式采样器 train_sampler = DistributedSampler( train_dataset, num_replicas=world_size, rank=rank ) # 创建数据加载器 train_loader = DataLoader( dataset=train_dataset, batch_size=32, sampler=train_sampler ) # 创建优化器 optimizer = torch.optim.Adam(model.parameters()) # 训练循环 for epoch in range(num_epochs): train_sampler.set_epoch(epoch) for batch in train_loader: # 前向传播 outputs = model(batch) loss = criterion(outputs, targets) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() cleanup() if __name__ == "__main__": world_size = torch.cuda.device_count() mp.spawn( train, args=(world_size,), nprocs=world_size, join=True )
启动命令:
python -m torch.distributed.launch --nproc_per_node=4 train.pytorch.distributed.launch 会自动为每个进程设置以下环境变量:
- LOCAL_RANK :当前进程在当前节点的 rank
- RANK :全局 rank
- WORLD_SIZE :总进程数
- MASTER_ADDR :主节点地址
- MASTER_PORT :主节点端口
一半情况下不需要手动指定,如果需要精细控制,则通过参数控制
方法详解
torch.squeeze() & torch.unsqueeze()
- squeeze
除去输入张量中数值为1的维度,并返回新的张量(输出的张量与原张量共享内存),
如果dim不指定,则删除所有值为1的维度;如果dim指定某个维度且该维度值为1,则执行删除,否则张量维度不变
- unsqueeze

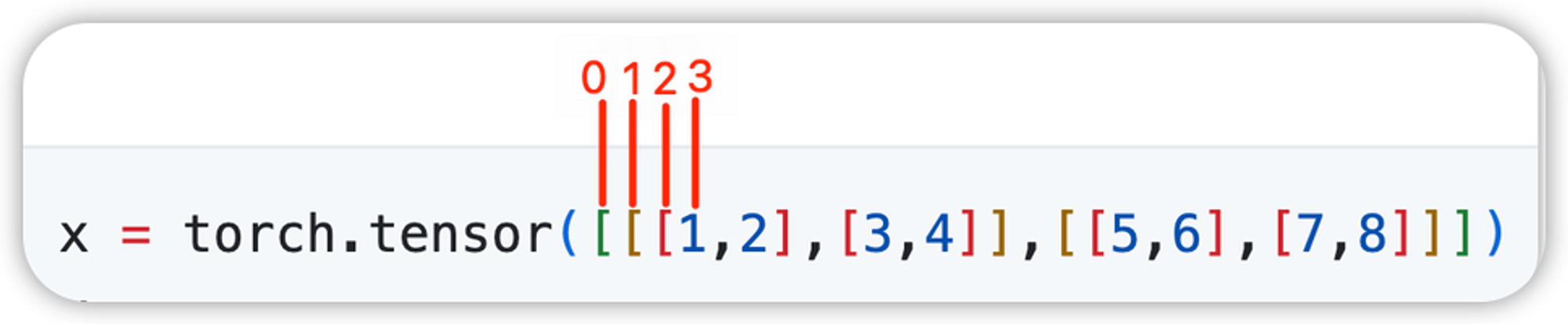
针对以上的一个三维张量,
当unsqueeze的参数是0时,torch.unsqueeze(z,0) 就是在索引为0的括号的外面再加一层括号,
当unsqueeze的参数是1时,torch.unsqueeze(z,1) 就是在索引为1 的括号前面加一层括号,
当unsqueeze的参数是2时,torch.unsqueeze(z,2) 就是在索引为2 的括号前面加一层括号,
当unsqueeze的参数是3时,torch.unsqueeze(z,3) 就是在最里面的数字上加一层括号
torch.cat() & torch.stack()
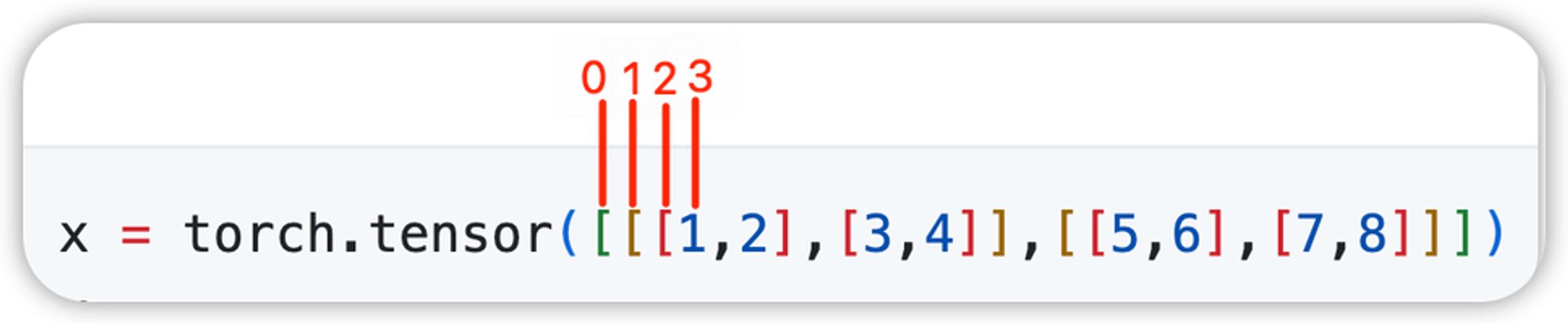
- cat


针对以上的一个三维张量,cat的合并维度由张量的维度决定,张量维度的索引范围:[-3, 2]
当cat的参数是0时,torch.cat((x, x, x), 0) 就是将三个x张量的第一层括号内的内容进行合并,
当cat的参数是1时,torch.cat((x, x, x), 1) 就是将三个x张量的第二层括号内的内容进行合并,
当cat的参数是2时,torch.cat((x, x, x), 2) 就是将三个x张量的第三层括号内的内容进行合并,
- stack
针对以上的一个三维张量,stack的合并维度由张量的维度决定,张量维度的索引范围:[-4, 3]
当cat的参数是0时,torch.stack((x, x, x), 0) 就是将三个x张量的第一层括号内的内容进行合并,并且在合并后的内容外增加一维,
当cat的参数是1时,torch.stack((x, x, x), 1) 就是将三个x张量的第二层括号内的内容进行合并,并且在合并后的内容外增加一维,
当cat的参数是2时,torch.stack((x, x, x), 2) 就是将三个x张量的第三层括号内的内容进行合并,并且在合并后的内容外增加一维,
当cat的参数是2时,torch.stack((x, x, x), 3) 就是将三个x张量的最内层内容进行合并,并且在合并后的内容外增加一维,
在指定轴上进行聚合运算
最值计算
x = torch.arange(24).reshape([2,3,4]) """ tensor([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) """ x[0,2,2] = 33 x.min(dim=0) # 此时轴为 0,其中有 2 个元素(此处为两个矩阵),将两个元素的对应位置进行比较(两个矩阵的对应位置的元素进行比较),返回最小值组成的矩阵及其对应的索引(因为只有两个元素,所以这个索引是在 0 和 1 之间);返回的结果会将轴 0 上的长度降为 0,所以返回的形状是:[3,4] """ torch.return_types.min( values=tensor([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 22, 11]]), indices=tensor([[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 1, 0]])) """ x[0,2,2] = -1 x.min(dim=1) # 此时轴为 1,其中有 3 个元素(此处三个向量),将三个元素的对应位置进行比较(三个向量的对应位置的元素进行比较),返回最小值组成的向量及其对应的索引(因为只有三个元素,所以这个索引是在 0、1、2 之间);返回的结果会将轴 1 上的长度降为 0,所以返回的形状是:[2,4] """ torch.return_types.min( values=tensor([[ 0, 1, -1, 3], [12, 13, 14, 15]]), indices=tensor([[0, 0, 2, 0], [0, 0, 0, 0]])) """ x[0,2,3] = -3 x.min(dim=2) # 此时轴为 2,其中有 4 个元素(此处四个标量),在四个元素(标量)中求最小值,返回最小值组成的向量及其对应的索引(因为有四个元素,所以这个索引是在 0、1、2、3 之间);返回的结果会将轴 2 上的长度降为 0,所以返回的形状是:[2,3] """ torch.return_types.min( values=tensor([[ 0, 4, -3], [12, 16, 20]]), indices=tensor([[0, 0, 3], [0, 0, 0]])) """
求和、求均值运算
x = torch.arange(24).reshape([2,3,4]) """ tensor([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) """ x.sum() # 不指定轴,求所有元素的总和 """ tensor(276.) """ x.sum(dim=0) # 此时轴为 0,其中有 2 个元素(此处为两个矩阵),将两个元素的对应位置进行相加(两个矩阵的对应位置的元素进行相加),返回求和后的矩阵;返回的结果会将轴 0 上的长度 2 降为 0,所以返回的形状是:[3,4] """ tensor([[12, 14, 16, 18], [20, 22, 24, 26], [28, 30, 55, 34]]) """ x.sum(dim=1) # 此时轴为 1,其中有 3 个元素(此处三个向量),将三个元素的对应位置进行相加(三个向量的对应位置的元素进行相加),返回求和后的向量;返回的结果会将轴 1 上的长度 3 降为 0,所以返回的形状是:[2,4] """ tensor([[12, 15, 7, 21], [48, 51, 54, 57]]) """ x.sum(dim=2) # 此时轴为 2,其中有 4 个元素(此处四个标量), 将四个元素进行相加,返回求和后的标量;返回的结果会将轴 2 上的长度 4 降为 0,所以返回的形状是:[2,3] """ tensor([[ 6, 22, 13], [54, 70, 86]]) """ x.sum(dim=[0,1]) # 求 0、1 轴上的和,最终返回值是将 0、1 轴的维度去掉,返回一个长度为 4 的向量;计算过程可以理解为先求 0 轴上的和,在此结果上再求 1 轴上的和。 """ tensor([60., 66., 61., 64.]) """ x = torch.arange(24).reshape([2,3,4]).float() # mean方法要求输入张量必须是浮点数,所以要进行转换;其返回的值的形状与sum 方法一至。 x.mean() x.mean(dim=0) x.mean(dim=1) x.mean(dim=2) x.mean(dim=[0,1]) # 累加求和 x = torch.arange(24).reshape([2,3,4]) x.cumsum(axis=0) """ tensor([[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]], [[12., 14., 16., 18.], [20., 22., 24., 26.], [28., 30., 32., 34.]]]) """ x.cumsum(axis=1) """ tensor([[[ 0., 1., 2., 3.], [ 4., 6., 8., 10.], [12., 15., 18., 21.]], [[12., 13., 14., 15.], [28., 30., 32., 34.], [48., 51., 54., 57.]]]) """ x.cumsum(axis=2) """ tensor([[[ 0., 1., 3., 6.], [ 4., 9., 15., 22.], [ 8., 17., 27., 38.]], [[12., 25., 39., 54.], [16., 33., 51., 70.], [20., 41., 63., 86.]]]) """