天猫复购预测-挑战赛——Top 0.5%
type
Post
date
Oct 30, 2023
summary
根据原数据构建了67个特征,尝试了多种算法和多次参数调优最终得分0.6925,记录过程分享一下。感觉数据指标还可以再优化,调参也还有进步空间,可以进一步优化提升。
category
学习笔记
tags
实战
机器学习
lightgbm
分类算法
算法大赛
password
URL
Property
Jun 20, 2025 01:47 AM
该比赛为学习赛,截止 20231027 参赛团队 18901 个,参赛地址 点这里

整体思路
比赛项目本质是一个二分类任务,而根据官方提供的数据,无法直接进行建模,所以第一步就是构建模型指标体系;第二步处理数据,最后进行建模。
数据挖掘有一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。所以整个项目的难点主要是在第一步。现在数据有了,我们的工作就是根据已有数据构建优质特征。那如何构建相对优质的特征呢?
这个问题没有系统性答案,不过总结来说,除了请教业务专家之外,还是要结合业务具体分析。比如针对当前任务来说,什么样的客户更有可能会产生复购行为呢?可以结合我们自己的购物习惯来分析。
- 用户购买能力:用户购买频率,用户整体转化率,用户购买偏好等
- 用户购买偏好:用户的忠诚度、消费商家范围等
- 商家受欢迎程度:体现在商家的复购率,用户转化率等
以上只是简单的列举,可以进一步扩散思考。而一些相同的特征可以对用户、商家、用户-商家都进行统计,以获取更多的数据知识供模型学习。
特征构建
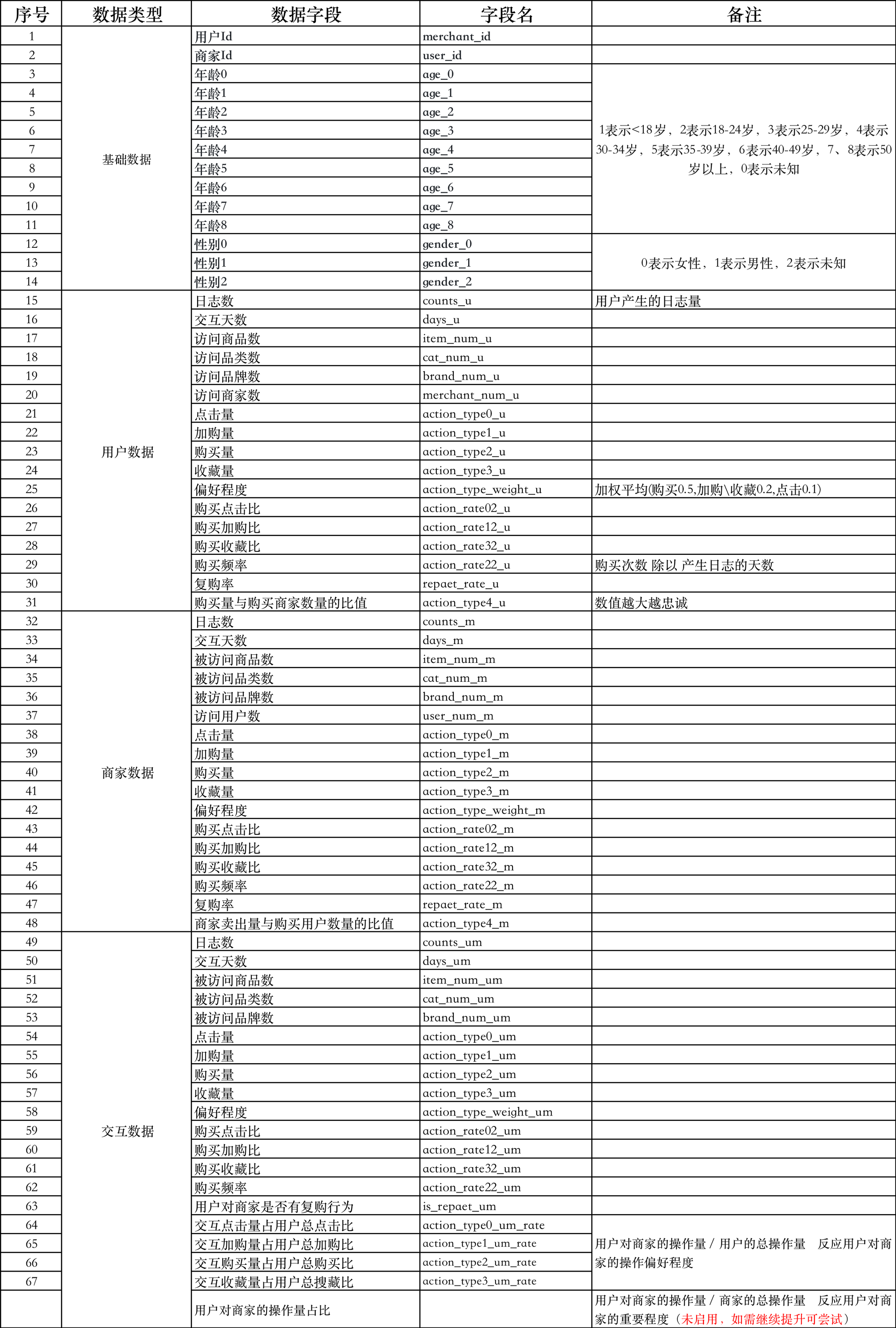
根据官方数据 data_format1 进行特征构建,构建特征的大致思路为:
- 基础数据:用户 Id、商家 Id、年龄、性别
- 用户行为数据:根据用户 Id 进行分组统计相关数据
- 商家行为数据:根据商家 Id 进行分组统计相关数据
- 用户与商家的交互数据:根据用户 Id 和商家 Id 分组进行相关统计
最终的数据字段详见下表:

数据处理
构建好特征之后,需要将数据处理成相应的字段,这里的处理方式就看跟人习惯了。我的处理方式是:
- 根据用户 Id 分组,统计相关的用户行为特征;
- 根据商家 Id 分组,统计相关的商家行为特征;
- 从训练数据中拿出需要的用户 Id 和商家 Id,将前两步的数据拼接到训练数据上;
- 根据训练数据的用户 Id 和商家 Id 筛选出相关的数据,再统计交互数据(减少数据量加快计算),并将交互数据拼接;
- 处理计算过程中产生的 inf(♾️)
数据处理具体代码如下:
# 用日志数据聚合计算用户在商家的操作行为(用户与对应商家的交互数据) def statistics(x,suf='_um'): x_valuse = x.values # 将df转换为array,提升计算效率 # display(x) result_base = { f'days{suf}': len(np.unique(x_valuse[:,5])), # 交互天数 f'counts{suf}': len(x_valuse[:,1]), # 日志数量 f'brand_num{suf}': len(np.unique(x_valuse[:,4])), # 品牌数量 f'cat_num{suf}': len(np.unique(x_valuse[:,2])), # 品类数量 f'item_num{suf}': len(np.unique(x_valuse[:,1])), # 商品数量 f'action_type0{suf}': sum(x_valuse[:,6]==0), # 点击量 f'action_type1{suf}': sum(x_valuse[:,6]==1), # 加购量 f'action_type2{suf}': sum(x_valuse[:,6]==2), # 购买量 f'action_type3{suf}': sum(x_valuse[:,6]==3), # 收藏量 # 偏好程度: 以上四个值加权平均(购买0.5,加购\收藏0.2,点击0.1) f'action_type_weight{suf}': (sum(x_valuse[:,6]==0)*0.1 + (sum(x_valuse[:,6]==1)+sum(x_valuse[:,6]==3))*0.2 + sum(x_valuse[:,6]==2)*0.5), f'action_rate02{suf}': sum(x_valuse[:,6]==2)/sum(x_valuse[:,6]==0), # 购买点击比 f'action_rate12{suf}': sum(x_valuse[:,6]==2)/sum(x_valuse[:,6]==1), # 购买加购比 f'action_rate32{suf}': sum(x_valuse[:,6]==2)/sum(x_valuse[:,6]==3), # 购买收藏比 f'action_rate22{suf}': sum(x_valuse[:,6]==2)/sum(np.unique(x_valuse[:,5])) # 购买频率 } def other_data(suf_inde): # 用户复购率 或 商家复购率 unique, counts = np.unique(x_valuse[x_valuse[:,6]==2][:,suf_inde], return_counts=True) # 购买数据去重统计 result_base[f'repaet_rate{suf}'] = np.sum(counts>1) / len(unique) # 用户购买量与购买商家数量的比值 或 商家卖出量与购买用户数量的比值 (数值越大越忠诚) result_base[f'action_type4{suf}'] = sum(x_valuse[:,6]==2)/len(np.unique(x_valuse[x_valuse[:,6]==2][:,suf_inde])) pass if suf=='_u': # 额外的用户数据 result_base[f'merchant_num{suf}'] = len(np.unique(x_valuse[:,3])) # 访问的商家数 other_data(3) elif suf=='_m': # 额外的商家数据 result_base[f'user_num{suf}'] = len(np.unique(x_valuse[:,0])) # 商家访问人数 other_data(0) else: # 额外的交互数据 # 用户对商家是否有复购行为 result_base[f'is_repaet{suf}'] = 1 if sum(x_valuse[:,6]==2)>1 else 0 return pd.Series(result_base) def concat_processing_data(data_format1): # ----- 连接用户数据,商家数据,基础信息,到标签数据 ----- # 以用户标签数据为主, 连接用户信息 data_info = data_format1.merge(user_info_format1,how='left',on='user_id') data_info['age_range'].fillna(0,inplace=True) #缺失值用0取代(分段处理并用独热编码) data_info['gender'].fillna(2,inplace=True) #缺失值用2取代(分段处理并用独热编码) data_info = data_info.join(pd.get_dummies(data_info.age_range, prefix = "age")) data_info = data_info.join(pd.get_dummies(data_info.gender, prefix = "gender")) data_info.drop(columns = ["age_range","gender"],inplace = True) # 将商家数据拼接到标签数据 data_info = data_info.merge(merchant_actions_df,how='left',on='merchant_id') # 将用户数据拼接到标签数据 data_info = data_info.merge(user_actions_df,how='left',on='user_id') print('输入数据形状:',data_format1.shape, '\n拼接用户基础信息,拼接商家总数据信息数据形状:',data_info.shape) # ----- 计算交互数据 ----- # 筛选训练集需要的日志数据 , 用标签数据中的user_id,merchant_id来筛选日志数据(减小数据量,提高计算效率) user_id_unique = list(data_info['user_id'].unique()) # 获取训练集中的用户ID merchant_id_unique = list(data_info['merchant_id'].unique()) # 获取训练集中的商家ID new_user_log_format1 = user_log_format1.query('user_id==@user_id_unique and merchant_id==@merchant_id_unique') # 筛选用户日志 print('用户总日志量数据形状:',user_log_format1.shape, '\n筛选之后日志量数据形状:',new_user_log_format1.shape) # 对筛选出来的数据进行聚合,统计用户与商家之间的互动数据(不区分双十一之前和当天) user_log_format1_gr = new_user_log_format1.groupby(['user_id','merchant_id']).apply(statistics) # display(user_log_format1_gr.head(1)) print('筛选日志聚合数据形状:',user_log_format1_gr.shape) # ----- 交互数据合并到大部队 ----- all_filed_data_df = data_info.merge(user_log_format1_gr, how='left', on=['user_id','merchant_id']) # 计算用户对某商家的操作占总操作的占比 for i in range(4): all_filed_data_df[f'action_type{i}_um_u_rate'] = all_filed_data_df[f'action_type{i}_um'] / all_filed_data_df[f'action_type{i}_u'] # all_filed_data_df[f'action_type{i}_um_m_rate'] = all_filed_data_df[f'action_type{i}_um'] / all_filed_data_df[f'action_type{i}_m'] all_filed_data_df.fillna(0 ,inplace=True) print('最终数据形状', all_filed_data_df.shape) print('--'*50) all_filed_data_df = all_filed_data_df.replace([np.inf, -np.inf], np.nan).fillna(0) return all_filed_data_df # 统计所有商家数据 merchant_actions_df = user_log_format1.groupby('merchant_id').apply(statistics, suf='_m').reset_index() # 统计所有用户数据 user_actions_df = user_log_format1.groupby('user_id').apply(statistics, suf='_u').reset_index() # 训练数据处理 # 拆分数据和标签 train_data_label_all = train_format1['label'] # 训练数据标签 train_data_value_all = train_format1[train_format1.columns.difference(['label'])] # 训练数据----未处理的数据 # 训练数据处理 all_filed_data_df = concat_processing_data(train_data_value_all) # 预测数据处理 forecast_data_value = test_format1[['user_id','merchant_id']] all_forecast_data_df = concat_processing_data(forecast_data_value)
构建模型
模型构建就相对简单,按照既定流程推进即可。经过模型选择,参数调整,效果评估,最终是用所有训练数据进行训练,然后预测提交。
我最终选择的是 LightGBM,使用网格搜索 5 折交叉验证来调的参数。不过在训练时得出的 auc 分数会比提交的分数略低,可能是因为在调参时没有是用全部数据,最终预测的模型是使用了所有的训练数据导致的。