Python办公自动化之 - Word
type
Post
date
Apr 13, 2023
summary
最近经常会写大量同质化类型的模型文档,于是就产生了用python脚本来提升效率的想法,并且趁此机会,记录一下实践过程和 python 工具库的使用方法
category
实践技巧
tags
办公
自动化
python-docx
Word
password
URL
Property
Feb 28, 2024 01:07 PM
前言
Python 办公自动化最近几年可以说是遍地的广告。但说实话,这东西只要你有 Python 语言的基础,网上随便找一个教程跟着操作一遍,基本就能有模有样的把脚本跑起来。
我写这篇文章的目的仅仅是我最近经常会写大量同质化类型的模型文档,于是就产生了用python脚本来提升效率的想法;同时也趁此机会,记录一下学习过程和方便以后查阅。
一、概述
Python 操作 Word 的库有很多,本文主要使用和介绍 python-docx 库,它能实现创建、读取、写入等功能,基本满足我们操作文档的日常需求。
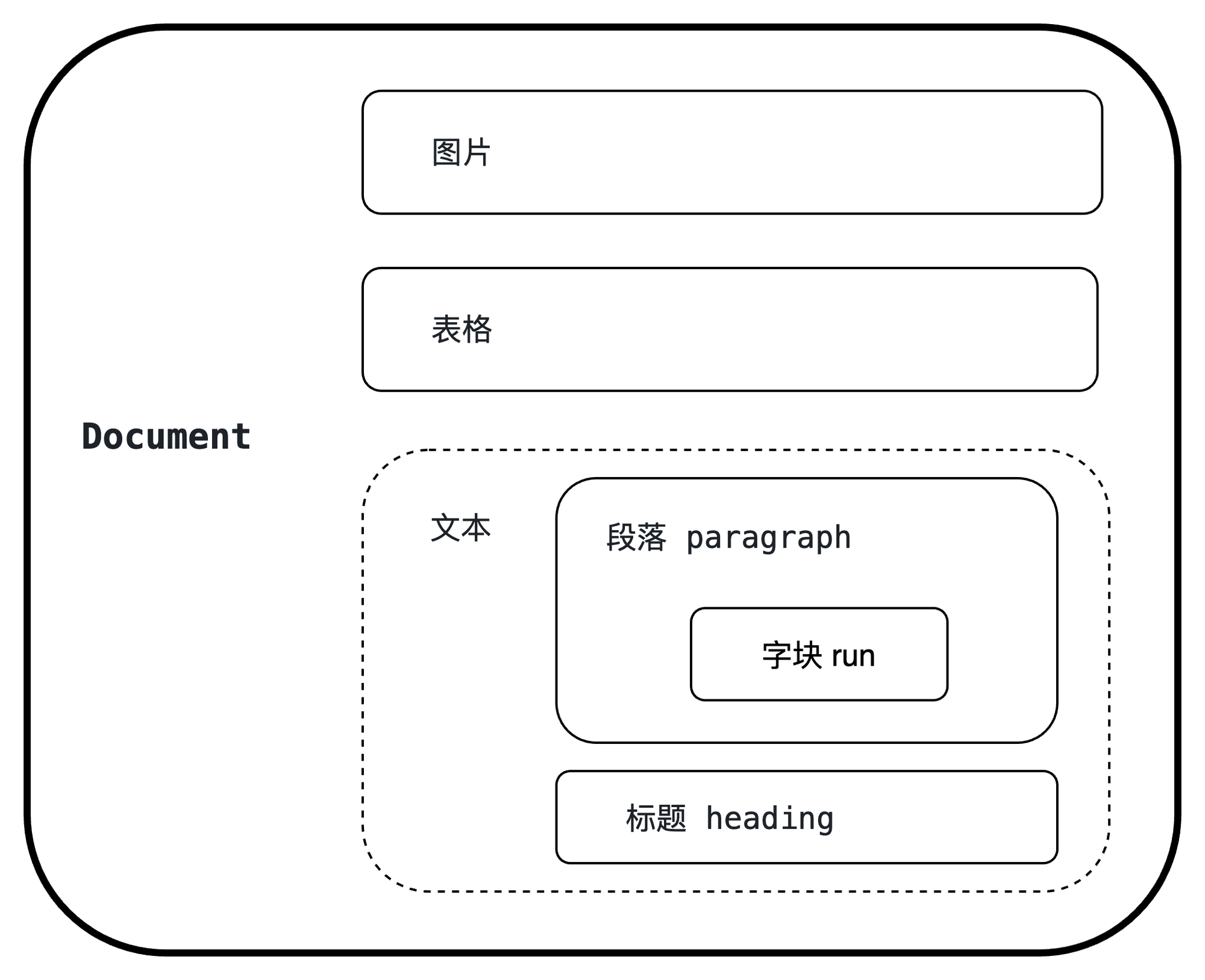
python-docx库可以实现对 Word 文档中图片、文本、表格等内容进行操作,而在文本内容的结构又被细分为了段落(paragraph)和字块(run),在我们实际操作 Word 的时候,每一次回车都会创建一个段落,字块更像是段落里面的一句一句的话(字块的结构可以想象成积木,一个段落由很多“积木”组成,积木的大小可以自己定义,可以是一段很长的话,也可以只是一个标点符号)。为了方便理解,示例图如下:

可以直接使用 pip 命令:
pip install python-docx 安装python-docx库,安装完成之后就可以开始进入正题了。二、方法速查
2.1、导包&实例化对象
# 导包 from docx import Document from docx.shared import Pt, RGBColor, Inches, Cm # 此模块中包含 docx 中各类单位方法 from docx.enum.table import WD_ALIGN_VERTICAL # 导入单元格垂直对齐 from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 导入段落对齐 from docx.oxml.ns import qn # 设置中文字体需导入 qn 模块 # 实例化一个Document对象 document = Document() # 如果给出文件路径,就是打开一个已经存在的文档,如果没有路径则创建一个新文档
2.2、读取内容&清空内容
### 读取文档内容(文档中的内容基本都保存在段落中,所以通过获取paragraphs即可) all_paragraphs = document.paragraphs for paragraph in all_paragraphs: paragraph_text = paragraph.text paragraph_runs = paragraph.runs for run in paragraph_runs: run_text = run.text ### 清空文档内容 for paragraph in all_paragraphs: p = paragraph._element p.getparent().remove(p) p._p = p._element = None
2.3、添加内容
2.3.1、添加标题
### 标题 document.add_heading('标题',0) document.add_heading(text="一级目录", level=1) document.add_heading(text="二级目录", level=2)
2.3.2、添加段落&字块&样式设置
### 段落 # 添加段落 paragraph1 = document.add_paragraph("这是第1个段落") paragraph1.insert_paragraph_before("额外插入的段落文字") # 在段落1之前插入 # 段落样式 number = document.add_paragraph("测试段落List Number", style="List Number") # 有序段落——前面有序号 bullet1 = document.add_paragraph("测试段落List Bullet 2", style="List Bullet 2") # 2级 无序段落——前面是黑点 bullet1.style = "List Bullet" # 重新设置段落样式为 1级无序 # 段落对齐 paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐 paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT # 左对齐 paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 右对齐 paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY # 两端对齐 paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.DISTRIBUTE # 分散对齐 # 段落格式 paragraph1.paragraph_format.line_spacing = 1.5 # 行间距,1.5倍行距 paragraph1.paragraph_format.line_spacing = Pt(20) # 行间距,固定值20磅 paragraph1.paragraph_format.first_line_indent = Pt(10) # 首行缩进10磅(首行缩进的单位支持Pt、Cm、Mm、Inches等,需要进行自己换算) paragraph1.paragraph_format.space_before = Pt(30) # 段前30磅 paragraph1.paragraph_format.space_after = Pt(15) # 段后15磅 ### 字块 paragraph2 = document.add_paragraph("这是第2个段落") # type: Paragraph run1 = paragraph2.add_run("追加的文字") run1.bold = True # 加粗 run1.italic = True # 斜体 run1.underline = True # 下划线 run1.text = "修改之后的文字" # 修改文本 run1.font.name = "Times New Roman" # 设置西文是新罗马字体 # run1.element.rPr.rFonts.set(qn('w:eastAsia'), '宋体') # 设置中文是宋体(未验证) run1.font.size = Pt(30) # 字号大小 run1.font.bold = False # 是否加粗 run1.font.italic = False # 是否斜体 run1.font.underline = False # 是否下划线 run1.font.shadow = True # 是否阴影 run1.font.color.rgb = RGBColor(56, 36, 255) # 字体颜色 # run1.font.color.rgb = RGBColor.from_string("ff0056") # 字体颜色
2.3.3、添加图片&调整大小
### 添加图片 document.add_picture(r"./test.png",width=Inches(6.0), height=Inches(6.0)) # 按英寸设置,只设置一个方向的值时,另一方向会自动缩放 document.add_picture(r"./test.png",width=Cm(6.0), height=Cm(6.0)) # 按厘米设置,只设置一个方向的值时,另一方向会自动缩放 # 图片对齐:图片实际是保存在段落中的,只需要对所在段落设置对齐方式即可;删除图片同理,后文会提到
2.3.4、添加表格&样式调整
### 表格 # 添加表格 table1 = document.add_table(5, 6) table1.style = 'Table Grid' # 也可以在创建时指定格式 table1.cell(0,0).text = '0' # 给表格单元格赋值 table1.add_column(Inches(3)) # 为表格对象增加列 table1.add_row() # 为表格对象增加行,只能逐行添加 table1.autofit = True # 表格设置自动调整列宽,(默认也为真) table1.cell(0,0).vertical_alignment = WD_ALIGN_VERTICAL.TOP # 垂直方向对齐,对齐方式:'TOP'-0, 'CENTER'-1, 'BOTTOM'-3, 'BOTH'-101 table1.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 水平方向对齐,对齐方式:'LEFT'-0, 'CENTER'-1, 'RIGHT'-2 row0 = table1.rows[0] # 获取行对象 col0 = table1.columns[0] # 获取列对象 row0_cells = table1.row_cells(0) # 获取表格一行的单元格对象列表 col_0_cells = table1.column_cells(0) # 获取一列的单元格对象列表 # 获取表格数据 tables = document.tables # 获取文档中所有表格对象的列表 table0 = tables[0] # 获取第一个表格 cells = table0._cells # 获取表格中的所有单元格 cells_string = [cell.text for cell in cells] # 获取单元格中的文本 col_num = len(table0.columns) # 获取表格对象列数 row_num = len(table0.rows) # 获取表格对象行数
2.3.5、添加分页符
### 添加分页符 document.add_page_break() # 实际上是调用新建段落的add_break(WD_BREAK.PAGE)
2.4、保存
### 保存word文件到当前文件夹 document.save("./test.docx") # 如果没有保存操作,那么写入不成功!
三、实践和问题
在实践过程中总会遇到和别人不一样的问题。在实践过程中,我的需求是将 Excel 中的数据读出来,然后写到 Word 中,并实现不同级别的包含关系。如下图,大体的需求是将不同列的数据作为不同级别的标题写入 Word。


解决代码如下(脱敏后的部分代码):
### excel 内容获取 def acquire_excel(workbook): sheet = workbook["sheet1"] # 获取 E 列的内容,作为 word 文档的三级目录 demand_name3 = sheet["E"][1:] demand_name3_list = [i.value for i in demand_name3 if i.value] # 获取 F 列的内容,作为 word 文档的 正文小标题 demand_name4 = sheet["F"][1:] demand_name4_list = [i.value for i in demand_name4] # 将三级和四级组合成字段,以便后续循环生成标题 dic1 = {} for i,v in enumerate([i.value for i in demand_name3]): if v: k = v dic1[k] = [demand_name4_list[i]] else: dic1[k].append(demand_name4_list[i]) return demand_name1,demand_name2,dic1 ### Word 写入内容 def wirt_docx(document,dic1): for k,v in dic1.items(): document.add_heading(k, level=3) for j,v_i in enumerate(v): # 添加段落 # document.add_paragraph(f'{j+1}.'+v_i+'\n') paragraph_j = document.add_paragraph() run1 = paragraph_j.add_run(f'{j+1}.'+v_i+'\n') run1.bold = True # 保存修改 document.save(docx_path)
其中 Excel 自动化操作详见:Python 办公自动化之 - Excel