Python办公自动化之 - Excel
type
Post
date
Apr 24, 2023
summary
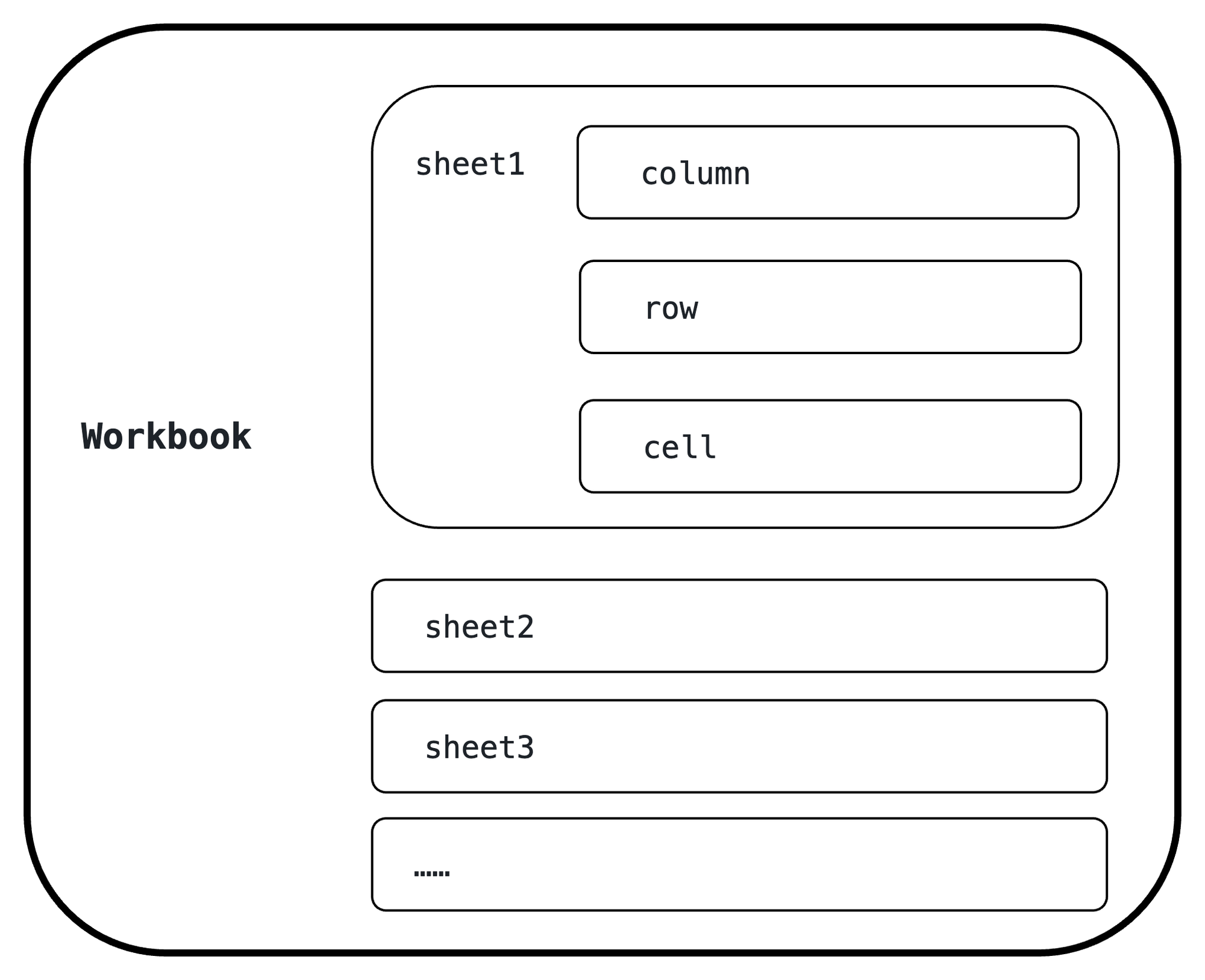
相比 Word 的内容,Excel 的内容看起来就清晰很多,一个 Excel 文件可以被实例化成一个 Workbook 对象,一个 Workbook 对象中可以包含多个 sheet 对象,每个 sheet 对象中又有行(row),列(column),单元格(cell)对象。
category
实践技巧
tags
办公
自动化
python
Excel
password
URL
Property
Feb 28, 2024 01:07 PM
前言
本文是 Python 办公自动化的第二篇,由于我对 Python 操作其他文件暂时也没有需求,所以应该也是最后一篇。第一篇可以看这里:Python 办公自动化之 - Word
同样的,Python 操作 Excel的三方库也很多,但本文主要介绍openpyxl库的用法和实际案例;用
pip install openpyxl即可自行安装,但如果你是第一次使用openpyxl 库,那你很可能还需要再单独安装 xmlx 这个依赖库:pip install xmlx。一、概述
相比 Word 的内容,Excel 的内容看起来就清晰很多,一个 Excel 文件可以被实例化成一个 Workbook 对象,一个 Workbook 对象中可以包含多个 sheet 对象,每个 sheet 对象中又有行(row),列(column),单元格(cell)对象。这样的层级结构和我们实际操作 Excel 文件差不多。具体的结构图如下:

而 openpyxl 操作 Excel 的逻辑也很简单,不管是读取数据还是写入数据,绕不开的一步都是要先定位到对应的 cell 所在的位置,定位到单元格位置之后用 cell.value 方法读取数据,用赋值 cell.value=xx 的方法写入数据,仅此而已;
额外的,还有一些调整 Excel 格式、样式的方法,下文详细介绍。
二、方法速查
# 导包 from openpyxl import load_workbook from openpyxl.styles import Font, PatternFill, Border, Side, Alignment
2.1、文档对象和sheet
### 文档对象和sheet workbook = load_workbook(filename = "./test.xlsx") # 实例化workbook对象;如果不输入路径,在save时输入路径则会新建一个Excel文件 workbook.create_sheet("new_sheet") # 创建新的 sheet workbook.remove("new_sheet") # 删除一个 sheet sheet_list = workbook.sheetnames # 获取 Excel 中所有的 sheet 名称,返回列表 sheet = workbook[sheet_list[0]] # 实例化 Excel 的第一个 sheet 对象 sheet.title = 'new_name' # 修改 sheet 名称 sheet = workbook.active # 实例化活跃的 sheet 对象(就是你用Office打开Excel时被打开的sheet)
2.2、单元格定位和数据
### 读取 ## 定位单个cell,获取数据 cell_A1 = sheet["A1"] # 坐标定位单元格 cell_A1 = sheet.cell(row=1,column=1) # 行列定位单元格 cell_value = cell_A1.value # 获取单元格数据 cell_row = cell_A1.row # 获取单元格所在行 cell_column = cell_A1.column # 获取单元格所在列 cell_coordinate = cell_A1.coordinate # 获取单元格坐标,Excel表达如:A1 cell_A1 = '我是写入的内容' # 向单元格写入数据 ## 定位范围 cells = sheet["A1:C2"] # 获取A1到C2范围的单元格 cells = sheet["A"] # 获取A列的数据 cells = sheet["A:C"] # 获取A,B,C三列的数据 cells = sheet[5] # 获取第5行的数据 cells = sheet.iter_rows(min_row=2, max_row=5, min_col=1, max_col=2) # 定位第二行到第五行,第一列到第二列的范围,一行一行的读 cells = sheet.iter_cols(min_row=2, max_row=5, min_col=1, max_col=2) # 定位第二行到第五行,第一列到第二列的范围,一列一列的读 rows = sheet.rows # 获取所有的行 columns = sheet.columns # 获取所有的列
2.3、追加、插入和删除
sheet.append(data) # 将data追加到sheet已有数据的后面(按行追加),data的格式有list, range or generator, or dict append([‘This is A1’, ‘This is B1’, ‘This is C1’]) # 列表,需要所有列都有数据,如果某一列没有,可以占坑 append({‘A’ : ‘This is A1’, ‘C’ : ‘This is C1’}) # 字典,通过列名来定位数据追加的位置 append({1 : ‘This is A1’, 3 : ‘This is C1’}) # 字典,通过列索引来定位数据追加的位置,所以是从1开始的 sheet.insert_cols(idx=4,amount=2) # 插入列,idx为插入的位置,amount为插入的数量,插入之后的列在原来的第4行的左边,可以理解为:插入一列作为第四列,只不过这里是插入多列 sheet.insert_rows(idx=5,amount=4) # 插入行,idx为插入的位置,amount为插入的数量,插入之后的行在原来的第5行的上边 sheet.delete_cols(idx=4,amount=2) # 删除列,从第四列开始,删除两列 sheet.delete_rows(idx=5,amount=4) # 删除行,从第五行开始,删除四行
2.4、样式设置
# 字体样式 font = Font(name = 字体名称, size = 字体大小, bold = 是否加粗, italic = 是否斜体, color = 字体颜色) font = Font(name="微软雅黑",size=20,bold=True,italic=True,color="FF0000") # 对齐样式 alignment = Alignment(horizontal = 水平对齐模式, vertical = 垂直对齐模式, text_rotation = 旋转角度, wrap_text = 是否自动换行) alignment = Alignment(horizontal="center",vertical="center",text_rotation=45,wrap_text=True) - 水平对齐:‘distributed’,‘justify’,‘center’,‘leftfill’, ‘centerContinuous’,‘right,‘general’; - 垂直对齐:‘bottom’,‘distributed’,‘justify’,‘center’,‘top’; # 边框样式 border = Border(left = Side(style=边线样式,color=边线颜色),right = 右边线样式,top = 上边线样式,bottom = 下边线样式) style参数的种类: 'double, ‘mediumDashDotDot’, ‘slantDashDot’,‘dashDotDot’,‘dotted’,‘hair’,'mediumDashed, ‘dashed’, ‘dashDot’, ‘thin’,‘mediumDashDot’,‘medium’, 'thick’from openpyxl.styles import Side,Borderfrom border = Border( left=Side(border_style='thin', color='000000'), right=Side(border_style='thin', color='000000'), top=Side(border_style='thin', color='000000'), bottom=Side(border_style='thin', color='000000'), ) # 填充样式 pattern_fill = PatternFill(fill_type = 填充样式,fgColor = 填充颜色) pattern_fill = PatternFill(fill_type="solid",fgColor="99ccff") GradientFill(stop=(渐变颜色 1,渐变颜色 2……)) gradient_fill = GradientFill(stop=("FFFFFF","99ccff","000000")) cell.font = font # 设置字体 cell.border = border # 设置边框 cell.fill = pattern_fill # 设置常规填充 cell.fill = gradient_fill # 设置渐变填充 cell.alignment = alignment # 设置居中对齐 # 行高样式 sheet.column_dimensions[1].height = 8 # 一行设置 sheet.column_dimensions['A'].width = 8 # 一列设置 sheet.row_dimensions.height = 50 # 整体设置 sheet.column_dimensions.width = 30 # 整体设置
2.5、其他设置
# 其他常用设置 sheet.dimensions # sheet中有内容的范围,返回Excel中的范围表达,如:'A1:H11' sheet.freeze_panes = "C3" # 冻结窗口 sheet.auto_filter.ref = "A1" # 给表格添加 “筛选器” sheet.auto_filter.ref = sheet.dimensions # 给所有列加筛选器 # 合并单元格 sheet.merge_cells("C1:D2") sheet.merge_cells(start_row=7,start_column=1,end_row=8,end_column=3)
2.6、使用Excel公式
使用公式很简单,就是将 Excel 中的等号和公式用引号包装成字符串,然后用占位符替换指定内容即可
for i in range(2,16): sheet[f"D{i}"] = f'=IF(RIGHT(C{i},2)="cm",C{i},SUBSTITUTE(C{i},"m","")*100&"cm")'
三、实践和问题
本次实践结合了一些爬虫的基础知识,爬虫的具体内容参见Python爬虫初阶。本次的的一个基本需求是爬取天天基金网的指定基金数据,将其数据写入到 Excel 中,并对其涨跌幅度进行计算和是否建议买入的判断;判断逻辑是当我上次买入之后,基金累计下跌超过 4%(4%定投法来自 B 站 up:深度研究员雷牛牛),则将【是否建议买入】这一列对应的行的值赋值为 1。
代码写完之后将其设置为 Mac 的定时任务(定时任务比较简单,后续也可以单独写一篇讲一讲),每个工作日下午 14:40 自动执行,然后为购买基金提供数据决策。
完整代码如下:
import os import re import json import time import warnings import requests import datetime # import numpy as np # import pandas as pd from openpyxl import load_workbook warnings.filterwarnings('ignore') # 浏览器头 headers = {'content-type': 'application/json; charset=utf-8', 'User-Agent': 'xxx'} # 请求头自行填写 # 获取预估数据 或 历史数据 def get_data(url, is_Fstimate): """_summary_ Args: url (_type_): 每个基金的URL,可能是今天的估值数据,也可能是当前基金所有的历史数据,通过is_Fstimate参数来区分 is_Fstimate (bool): 用来区分基金 url 类型,1 为估值数据,0 为历史数据 Returns: _type_: 返回处理好的数据格式 """ r = requests.get(url, headers=headers) # 返回信息 content = r.text # print(url, content) if is_Fstimate: # 正则表达式 pattern = r'^jsonpgz\((.*)\)' # 查找结果 search = re.findall(pattern, content) data = json.loads(search[0]) else: # 正则表达式 pattern = r'Data_netWorthTrend = \[(.*?)\]' # 查找结果 search = re.findall(pattern, content) # search的形状是['{},{},{},{}'],但是loads能处理的形状是:1、json中只有一个字典的情况:'{}' 或者 2、json中只有多个字典的情况'[{},{},{},{}]' # print(search) # print(search[0]) search = '[' + search[0] + ']' data = json.loads(search) data = data[::-1] # 列表反转 return data # 时间转换函数 def timeTransformation(datetime): """_summary_ Args: datetime (_type_): 数据日期,当前为时间戳,粗腰处理成日期 Returns: _type_: 处理好的日期 """ datelocal = time.localtime(datetime) datetime_ = time.strftime("%Y-%m-%d %H:%M:%S", datelocal) date = datetime_[:10] return date # 写入历史数据 def write_history_data(history_data, sheet, all_date=None, omit_date_len=0, is_rewirte=0): """_summary_ Args: history_data (_type_): api 中获取到的历史数据 sheet (_type_): 当前基金对应的 sheet omit_date_len (_type_): 是否有断层数据 is_rewirte (int, optional): 是否需要重写所有数据,可能导致数据错位,慎重选择. Defaults to 0. """ if is_rewirte==1: # 完全重写历史数据,买入信息可能会错位,慎重选择 for r in range(len(history_data)): date_r = timeTransformation(int(history_data[r]['x']/1000)) sheet.cell(row=r+3, column=1).value = date_r # 日期 sheet.cell(row=r+3, column=2).value = history_data[r]['y'] # 净值 sheet.cell(row=r+3, column=3).value = history_data[r]['equityReturn'] # 涨幅 else: if omit_date_len>0: # 如果断层数据大于0天,则将断层数据插入表中(一般这个值小于等于 0) for m in range(omit_date_len): sheet.insert_rows(idx=3+m, amount=1) date_m = timeTransformation(int(history_data[m]['x']/1000)) sheet.cell(row=3+m, column=1).value = date_m # 日期 sheet.cell(row=3+m, column=2).value = history_data[m]['y'] # 净值 sheet.cell(row=3+m, column=3).value = history_data[m]['equityReturn'] # 涨幅 else: # 将昨天的预估数据更新为实际历史数据 latestDate = timeTransformation(int(history_data[0]['x']/1000)) if latestDate not in all_date: sheet.insert_rows(idx=3, amount=1) row = 3 else: is_A = [i.value for i in sheet['A']] # 获取A列数据 is_A_index = [i for i,v in enumerate(is_A) if v==latestDate] # 获取A列时间为昨天的行的索引 row = is_A_index[0] + 1 sheet.cell(row=row, column=1).value = timeTransformation(int(history_data[0]['x']/1000)) # 日期 sheet.cell(row=row, column=2).value = history_data[0]['y'] # 净值 sheet.cell(row=row, column=3).value = history_data[0]['equityReturn'] # 涨幅 # 写入预估数据 def write_estimat_data(estimate_data, sheet, all_date): # 如果不用重新写入,则需要将最新的历史数据和预估数据插入到表中 if estimate_data['gztime'][:10] not in all_date: sheet.insert_rows(idx=3, amount=1) # 预估数据插入 sheet.cell(row=3, column=1).value = estimate_data['gztime'][:10] sheet.cell(row=3, column=2).value = float(estimate_data['gsz']) sheet.cell(row=3, column=3).value = float(estimate_data['gszzl']) # print(estimate_data['gztime'][:10],float(estimate_data['gsz']),float(estimate_data['gszzl'])) # 计算累计涨跌幅(从最高点的跌幅) def whetherNotToBuy(sheet): ## 获取上次购买数据所在的行,判断购买的规则为:建议购买==1 and 购买金额不为0 is_F = [i.value for i in sheet['F']] # 获取E列数据 is_G = [i.value for i in sheet['G']] is_F_index = [i for i,v in enumerate(is_F) if v==1 and is_G[i] != None] # 获取买入点的数据索引 if len(is_F_index)<1: return else: row = is_F_index[0] # 上次购买所在的行数的前一行 ## 计算买入之后累计涨跌幅度 for i in range(row-2): # 减去两行表头 sheet[f'D{row-i}'] = sum([j.value for j in sheet['C'][row-i-1:row]]) # row-i-1是由于sheet中切片是前闭后开的,所以要减去一行 ## 计算买入之后从最高点的跌幅 B_list = [i.value for i in sheet['B'][2:row]] # 获取自上次买入后的净值数据,sheet中切片是前闭后开的,这里相当于是从第3行取到第row行 # 获取最大净值所在的行号 if len(B_list)==0: max_row = 3 else: max_row = B_list.index(max(B_list))+3 # 最大值行号为 3 的话,说明上一天才买入 if max_row==3: pass else: for i in range(1,max_row-2): # 减去两行表头 sheet[f'E{max_row-i}'] = sum([j.value for j in sheet['C'][max_row-i-1:max_row-1]]) # row-i-1是由于sheet中切片是前闭后开的,所以要减去一行 if sheet[f'E{max_row-i}'].value >= -4: sheet[f'F{max_row-i}'] = 0 else: sheet[f'F{max_row-i}'] = 1 def invoking_func(codes,workbook): sheetnames = workbook.sheetnames for code in codes: # 生成链接 url_estimate = "http://fundgz.1234567.com.cn/js/%s.js"%code url_history = "http://fund.eastmoney.com/pingzhongdata/%s.js"%code # 获取数据 estimate_data = get_data(url_estimate, True) # 前一天的更新数据和当天的预估数据 history_data = get_data(url_history, False) # 所有历史数据 ##### 数据入表 ##### # 如果 sheet 不存在,创建sheet并写入数据 if estimate_data['name'] not in sheetnames: workbook.create_sheet(estimate_data['name']) sheet = workbook[estimate_data['name']] # 表头写入 cells = ['A1','A2','B2','C2','D2','E2','F2','G2'] columns = ['基金代码:' + code, '交易日期','单位净值','净值涨跌','自上次买入累计涨跌','自买入后最大值累计跌幅','是否建议买入','买入金额'] for p in zip(cells,columns): sheet[p[0]] = p[1] # 写入所有历史数据 write_history_data(history_data, sheet,is_rewirte=1) # 写入预估数据 all_date = [sheet['A'][a].value for a in range(len(sheet['A']))][2:] # 更新表中的时间数据,否则会把最新的预估数据和最新的历史数据都写进去 write_estimat_data(estimate_data, sheet, all_date) else: sheet = workbook[estimate_data['name']] # 表中已有的数据的所有日期 all_date = [sheet['A'][a].value for a in range(len(sheet['A']))][2:] # 写入历史数据 (完全重写和更新最新历史数据(昨天数据),完全重写会导致买入信息错位,慎重选择) is_rewirte = 0 # 是否需要完全重写数据 omit_date_len = len(history_data) - len(all_date) # 数据缺失天数 write_history_data(history_data, sheet, all_date, omit_date_len, is_rewirte=0) # 写入预估数据 all_date = [sheet['A'][a].value for a in range(len(sheet['A']))][2:] # 更新表中的时间数据,否则会把最新的预估数据和最新的历史数据都写进去 write_estimat_data(estimate_data, sheet, all_date) # 计算距离上次买入的涨跌 whetherNotToBuy(sheet) # 保存数据 workbook.save('./基金数据买卖点.xlsx') if __name__ == "__main__": # 基金代码,自行更改为关注的基金代码 codes = ['161725', '005827', '003095','004788','014528','516160'] # 获取表格对象 workbook = load_workbook('./基金数据买卖点.xlsx') # 调用函数 invoking_func(codes,workbook) print('完成')
最终效果展示

