机器学习模型评估方法
type
Post
date
Oct 24, 2023
summary
在选择算法进行建模的时候,每种类型的算法中都有如此多可以用,我们如何选择一个最契合当前数据的模型?模型训练完之后,我们如何知道这个模型的效果?本文整理了机器学习中一些常用的评估方法
category
学习笔记
tags
机器学习
模型评估
模型选择
password
URL
Property
Jun 20, 2025 01:47 AM
一、回归模型评估
1.1、平均绝对误差 MAE(mean absolute error)

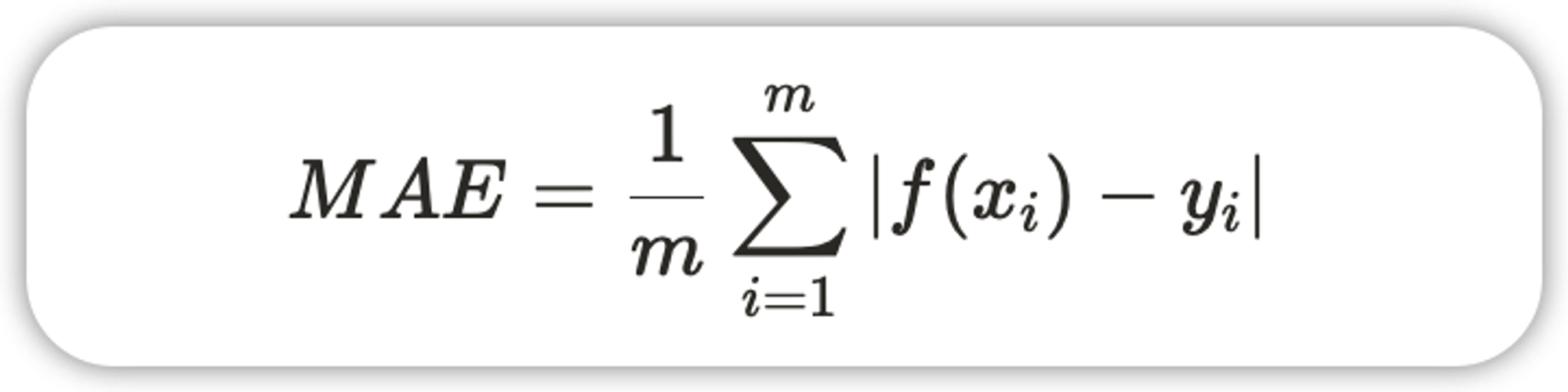
- 优点:直观地反映回归模型的预测值与实际值之间的偏差。准确地反映实际预测误差的大小。不会出现平均误差中误差符号不同而导致的正负相互抵消。
- 缺点:不能反映预测的无偏性(估算的偏差就是估计值的期望与真实值的差值。无偏就要求估计值的期望就是真实值)。
1.2、平均绝对百分误差 MAPE(Mean Absolute Percentage Error)
虽然平均绝对误差能够获得一个评价值,但是你并不知道这个值代表模型拟合是优还是劣,只有通过对比才能达到效果。当需要以相对的观点来衡量误差时,则使用MAPE。

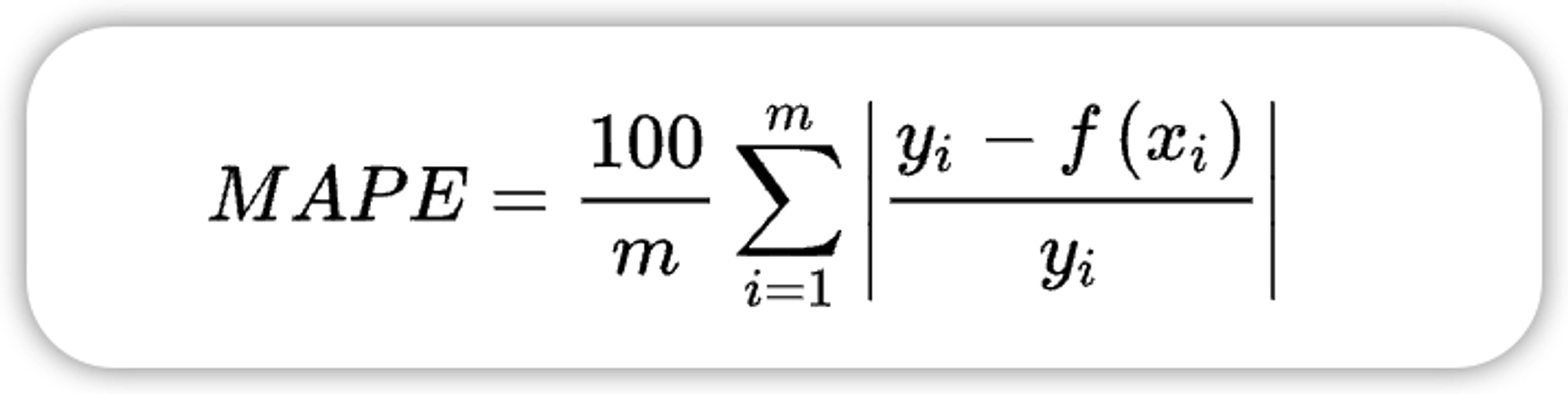
1.3、均方误差 MSE(mean squared error)
MAE虽能较好衡量回归模型的好坏,但是绝对值的存在导致函数不光滑,在某些点上不能求导。可以考虑将绝对值改为残差的平方,就得到了均方误差。均方误差求的是所有标签值与回归模型预测值的偏差的平方的平均。

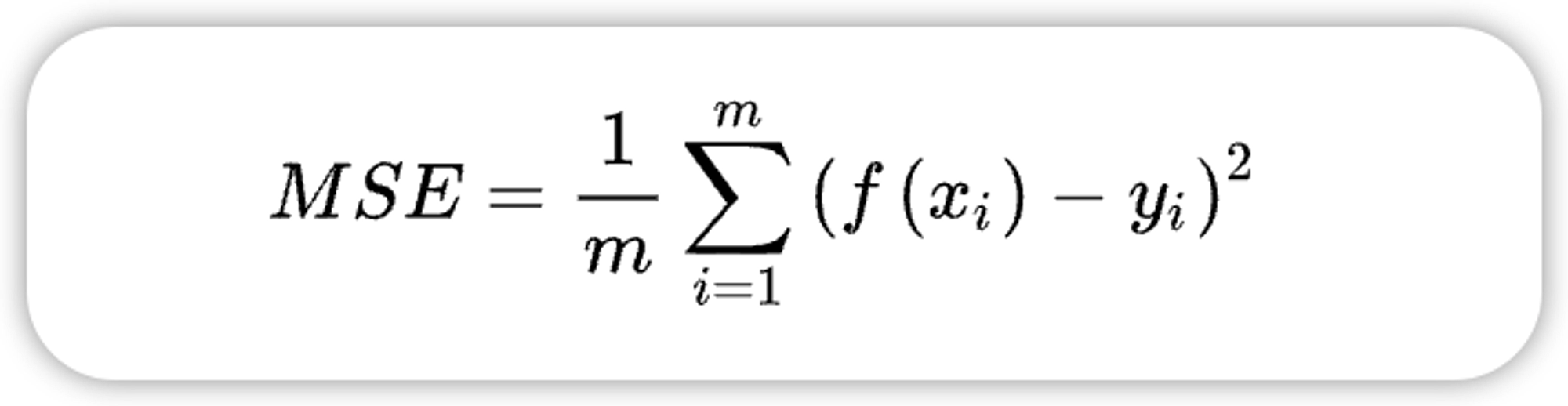
- 优点:准确地反映实际预测误差的大小。放大预测偏差较大的值。比较不同预测模型的稳定性。
- 缺点:不能反映预测的无偏性。
1.4、均方根误差 RMSE(root mean squared error)
均方根误差也称标准误差,是在均方误差的基础上进行开方运算。RMSE会被用来衡量观测值同真值之间的偏差。

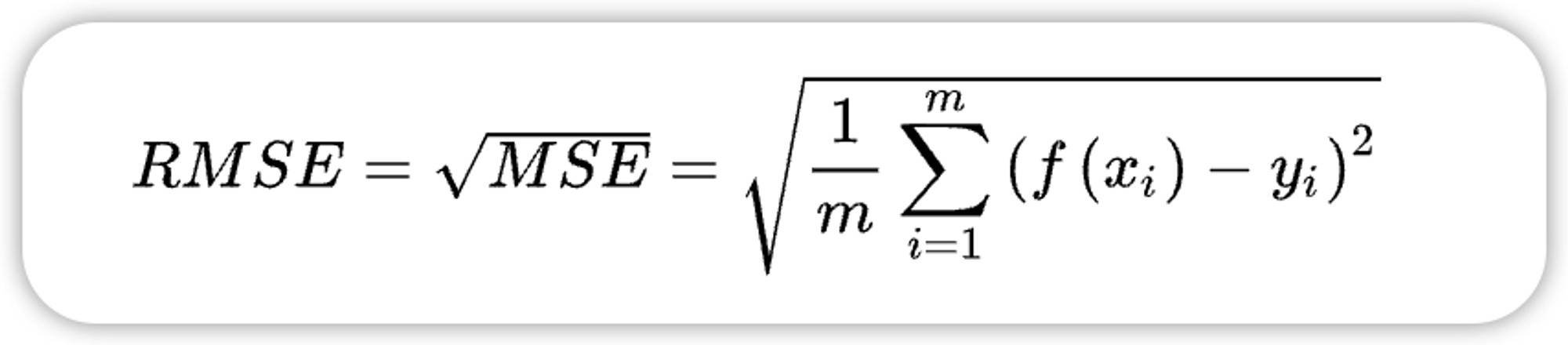
1.5、决定系数
决定系数 平方表征的是因变量 y 的变化中有多少可以用自变量 x 来解释,是回归方程对观测值拟合程度的一种体现。
越接近 ,说明回归模型的性能越好,即能够解释大部分的因变量变化。


- SSR:Sum of Squares of the Regression,即预测数据与原始数据均值之差的平方和,反映的是模型相对原始数据均值的离散程度。
- SST:Total Sum of Squares,即原始数据和均值之差的平方和,反映的是原始数据相对均值的离散程度。
- SSE:Sum of Squares for Error,残差平方和,原始数据和预测数据之差的平方和。
1.6、校正决定系数
在利用 来评价回归方程的优劣时,随着自变量个数的不断增加, 平方将不断增大。而校正决定系数则可以消除样本数量和特征数量的影响。

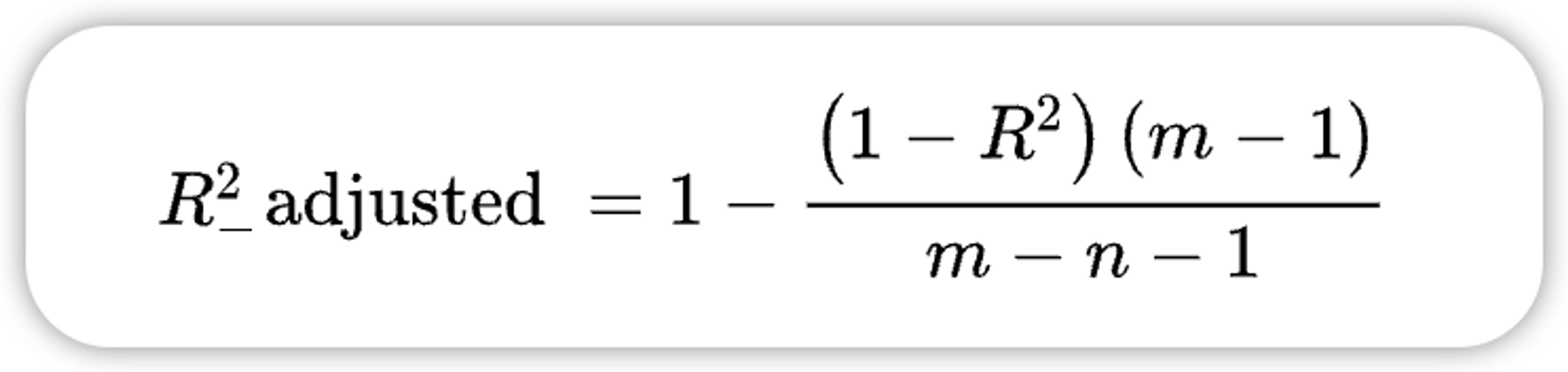
• 优点:在决定系数 的基础上考虑了特征个数的影响。比较变量数不同的模型。
1.7、选择
MAE、MSE、RMSE 均存在求平均的操作(包括R的平方也可以认为有此操作,只是因为分子分母的约分导致求平均的操作不明显),而取均值是为了消除样本数量的影响,使得评估指标的大小不会太依赖于样本数量,而是更多地反映模型的误差。
校正之后的决定系数在此基础上消除了样本数量和特征数量的影响,自变量越多,校正决定系数就会对自变量进行处罚,所以一般校正决定系数小于决定系数,它能更好地反映模型的质量,可以用来选择不同特征数量的回归模型。
1.8、sklearn 实现
校正决定系数需要手动实现
from sklearn.metrics import mean_absolute_error # 平均绝对误差 from sklearn.metrics import mean_absolute_percentage_error # 平均绝对百分误差 from sklearn.metrics import mean_squared_error # 均方误差 from sklearn.metrics import r2_score # 决定系数 mean_absolute_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average') mean_squared_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average') np.sqrt(mean_squared_error(y_test,y_pred)) # 均方根误差 mean_absolute_percentage_error(y_true, y_pred) r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
负均方误差:虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评 判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候, 会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中, 所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是 neg_mean_squared_error去掉负号的数字。
二、二分类模型评估
2.1、TP、TN、FP、FN解释说明(二分类混淆矩阵)

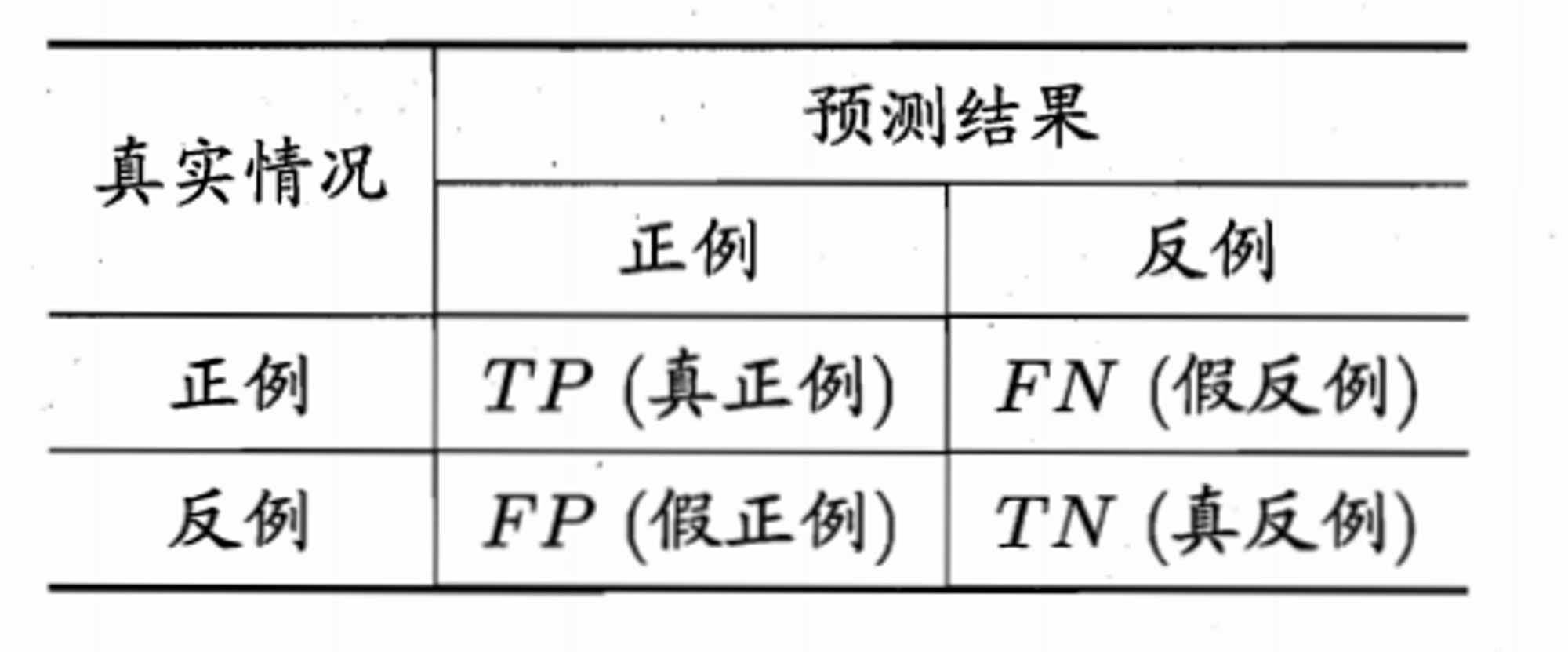
- TP:True Positive, 被判定为正样本,事实上也是正样本。
- FP:False Positive,被判定为正样本,但事实上是负样本。
- TN:True Negative, 被判定为负样本,事实上也是负样本。
- FN:False Negative,被判定为负样本,但事实上是正样本。
2.1、准确率(Accuracy)

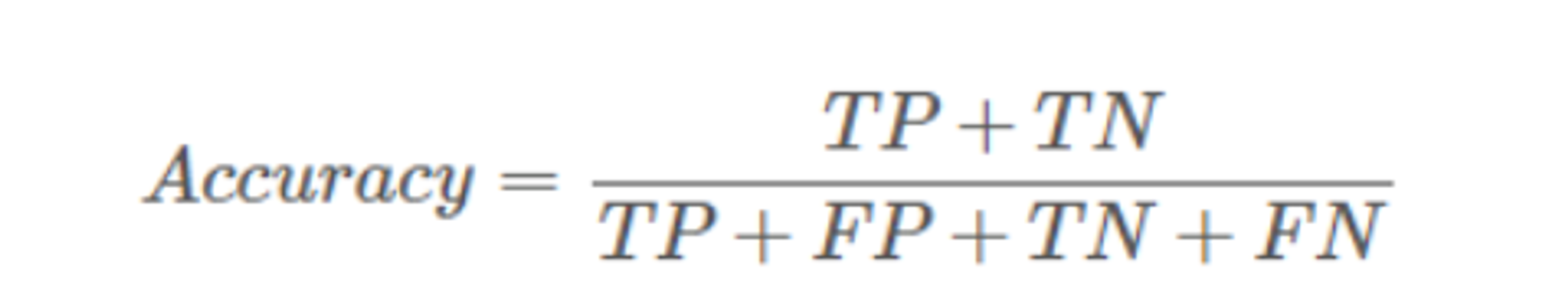
识别准确的量 / 总样本量
缺点:样本不均衡时影响评估效果
2.2、precision(精确率、查准率)

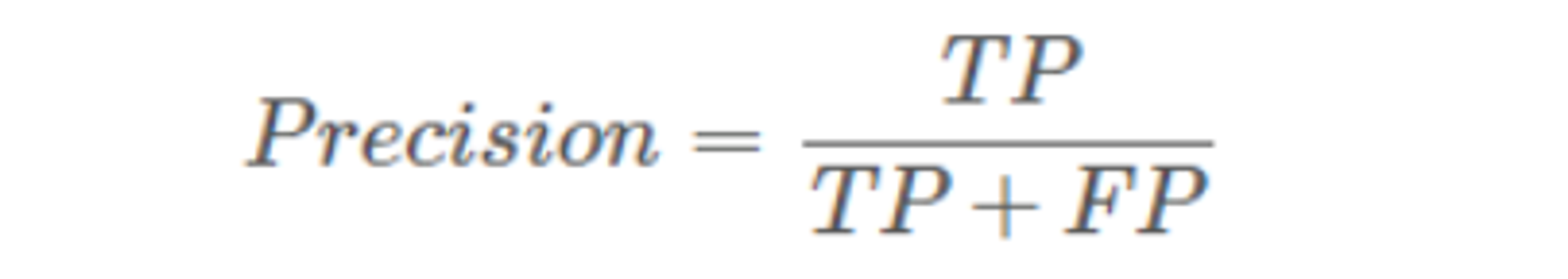
被模型识别为正样本中真正的正样本 / 被模型识别为正样本量
又称为查准率,
2.3、recall(召回率、查全率)

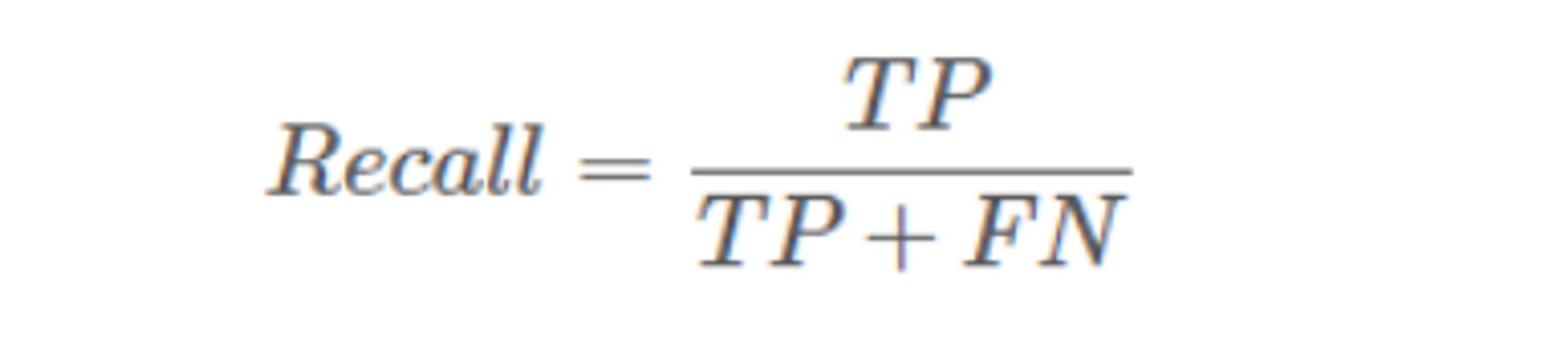
识别对了的正样本量 / 实际总的正样本量
又称为查全率:表示在原始样本的正样本中,最后被正确预测为正样本的概率
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,
2.4、F-Score
在实际中常常需要根据具体情况对精确率和召回率做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。而像癌症检测、地震检测、金融欺诈等,则在保证精确率的条件下,尽量提升召回率。
为此引出了一个新的指标F-score,综合考虑Precision和Recall的调和值

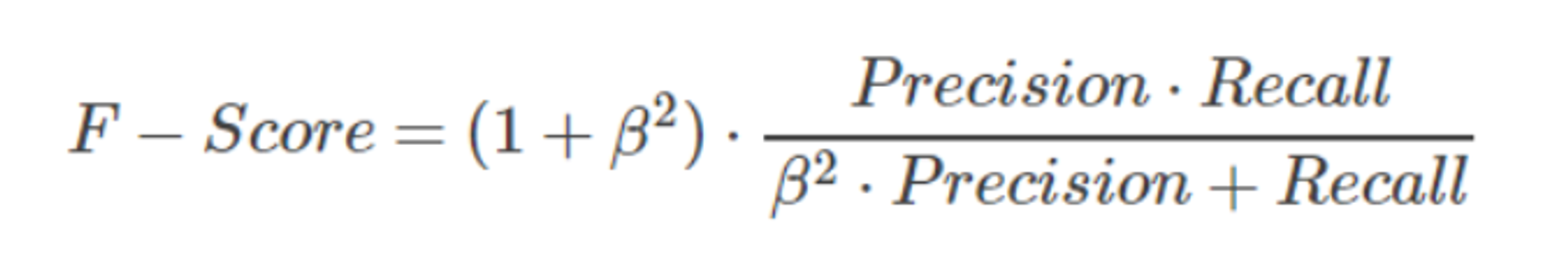
- 当
β=1时,称为F1-score或者F1-Measure,这时,精确率和召回率都很重要,权重相同。
- 当有些情况下,我们认为精确率更重要些,那就调整
β的值小于1,
- 如果我们认为召回率更重要些,那就调整
β的值大于1。
2.4.1、F1-Score
F1-score表示的是precision和recall的调和平均评估指标。


举个例子:癌症检查数据样本有10000个,其中10个数据祥本是有癌症,其它是无癌症。假设分类模型在无癌症数据9990中预测正确了9980个,在10个癌症数据中预测正确了9个,此时真阳=9,真阴=9980,假阳=10,假阴=1。
那么:
Accuracy = (9+9980) /10000=99.89% Precision=9/19+10)= 47.36% F1-score=2×(47.36% × 90%)/(1×47.36%+90%)=62.07% F2-score=5× (47.36% × 90%)/(4×47.36%+90%)=76. 27%
2.5、PR曲线 & AUC-PR
2.5.1、PR曲线(Precision-Recall Curve)
PR曲线是根据分类模型在不同的阈值下计算得到的精确率(Precision)和召回率(Recall)之间的关系绘制而成的曲线。横轴是召回率(Recall),纵轴是精确率(Precision)。曲线上的每个点对应于一个特定的分类阈值。通过改变阈值,可以得到不同的精确率和召回率。

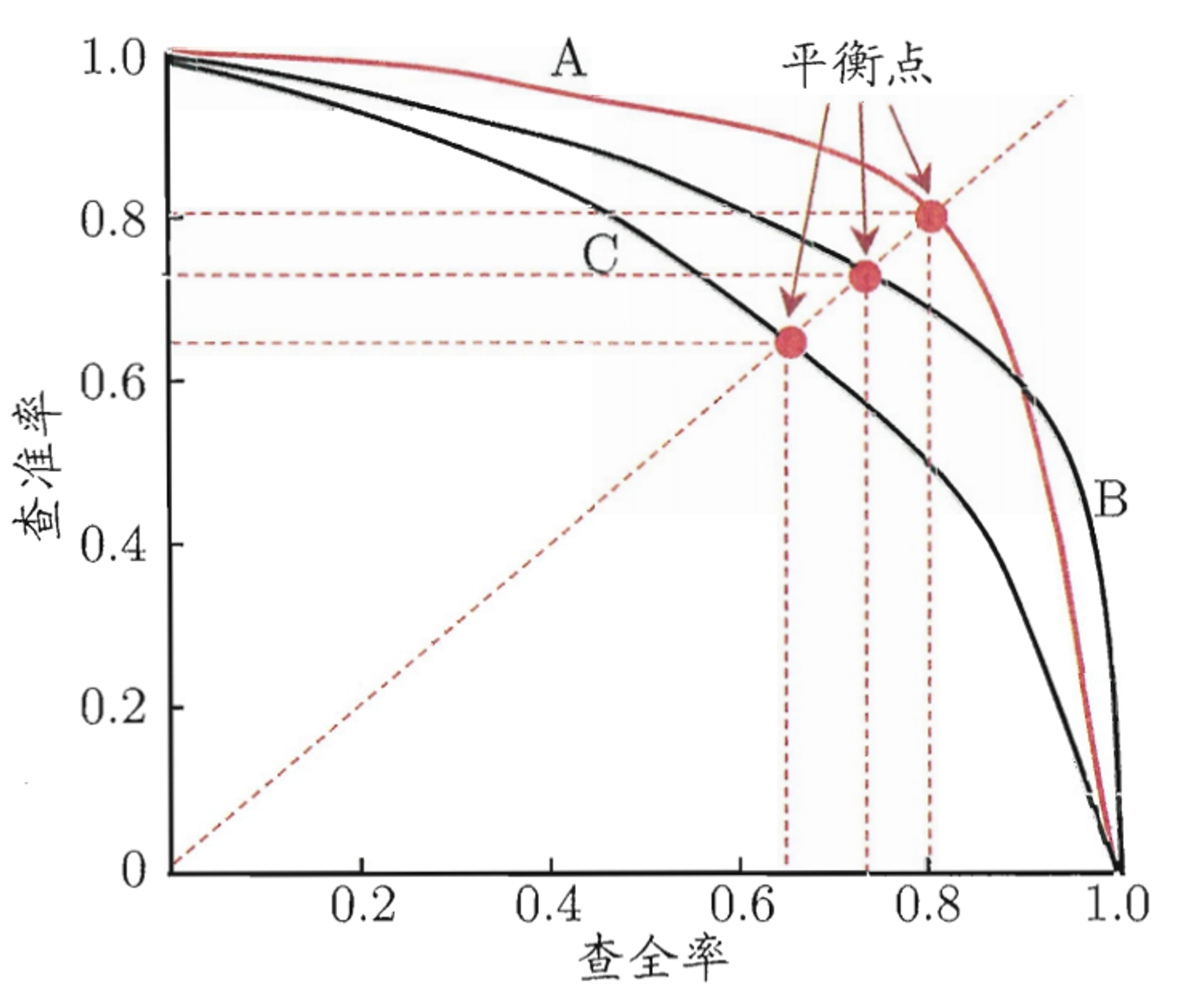
- 若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者,如图中学习器A的性能优于学习器C;
- 如果两个学习器的P-R曲线发生了交叉,如图中的A与B,则难以一般性地断言两者孰优孰劣? 只能在具体的查准率或查全率条件下进行比较.
然而, 在很多情形下,人们往往仍希望把学习器A与B比出个高低.这时一个比较合理的判据是比较P-R曲线下面积的大小, 它在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。但这个值不太容易估算,因此,人们设计了一些综合考虑查准率、查全率的性能度量
“平衡点”(Break Event Point,简称BEP )就是这样一个度量,它是“查准率=查全率”时的取值, 如图中学习器C的BEP 是0.64, 而基于BEP的比较,可认为学习器A 优于B。但BEP 还是过于简化了些,更常用的是Fl 度量
2.5.2、AUC-PR(Area Under the Precision-Recall Curve)
PR曲线下的AUC面积,反映了模型在正类样本中的查全率与查准率之间的平衡。AUC-PR的值范围在0到1之间,数值越大表示模型性能越好。
具体实现方法见
2.6、ROC曲线 & ROC-AUC
2.26.1、ROC曲线(Receiver Operating Characteristic Curve)
ROC曲线是根据分类模型在不同的阈值下计算得到的真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)之间的关系绘制而成的曲线。真阳性率定义为实际为正类的样本中被正确预测为正类的比例,假阳性率定义为实际为负类的样本中被错误预测为正类的比例。
真正例率 (TPR) 是召回率的同义词,TPR指实际正样本中被预测正确的概率。计算公式如下:

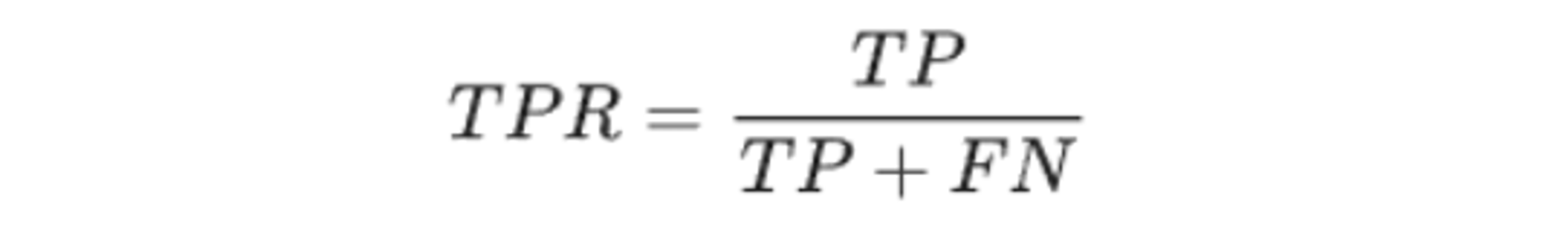
FPR指实际负样本中被错误预测为正样本的概率。计算公式如下:

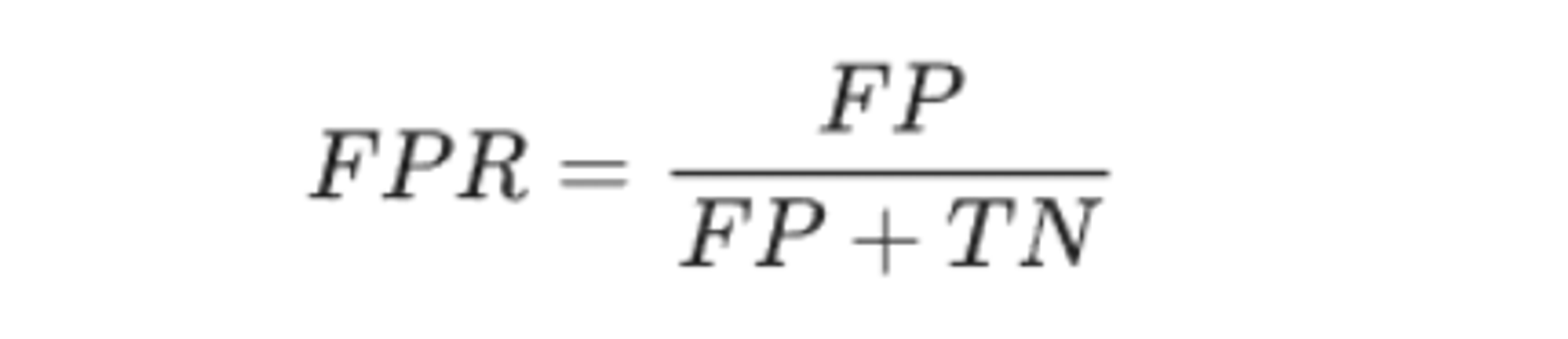
ROC曲线的横轴是FPR(假阳性率),纵轴是TPR(真阳性率)。曲线上的每个点对应于一个特定的分类阈值。通过改变阈值,可以得到不同的真阳性率和假阳性率。

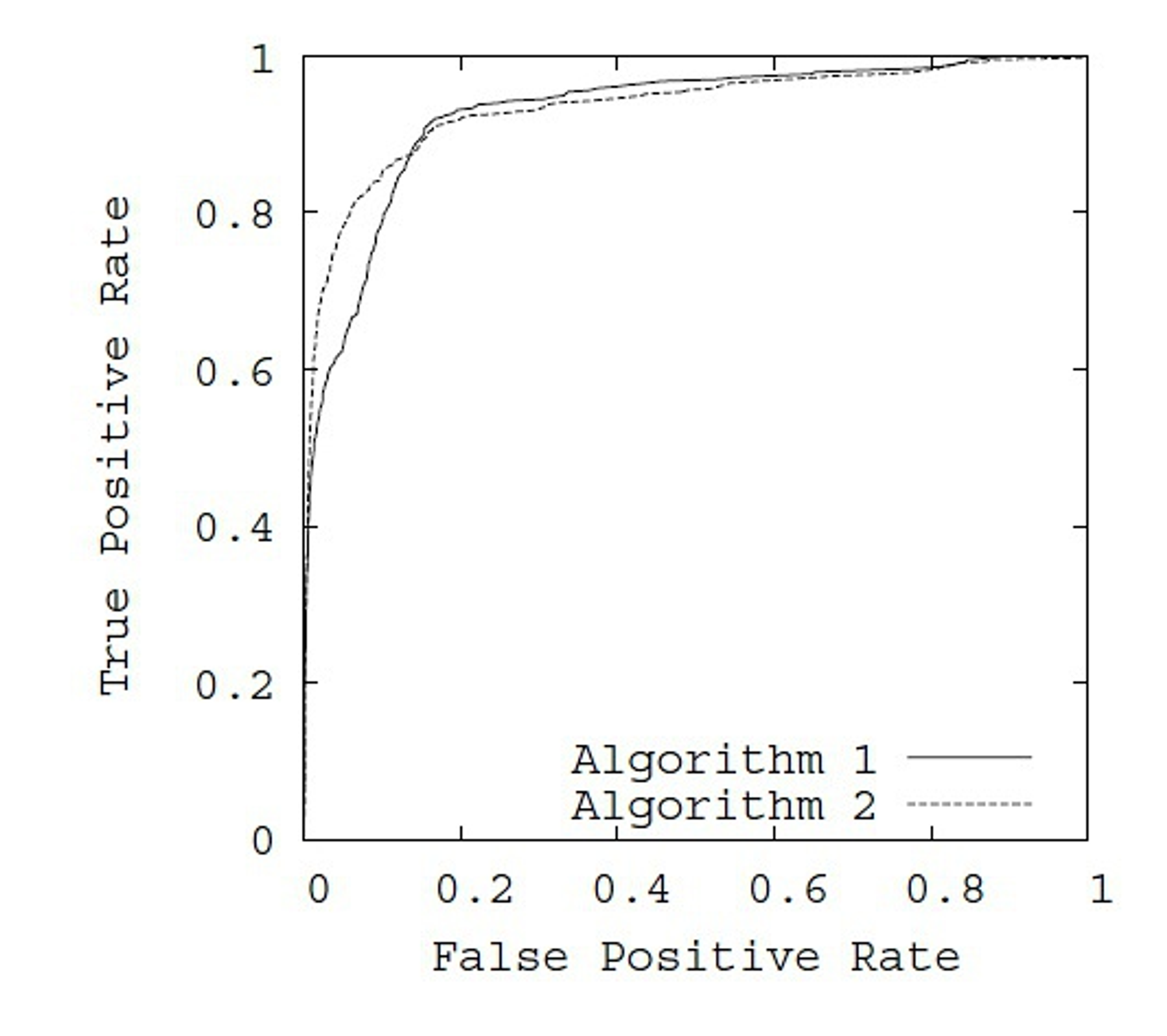
2.6.2、ROC-AUC
ROC曲线下的AUC面积,也称为AUC-ROC(Area Under the ROC Curve),反映了模型在正负样本之间的区分能力。AUC-ROC的值范围在0到1之间,但不表示数值越大越好。
面积如下图所示,阴影部分即为AUC面积:

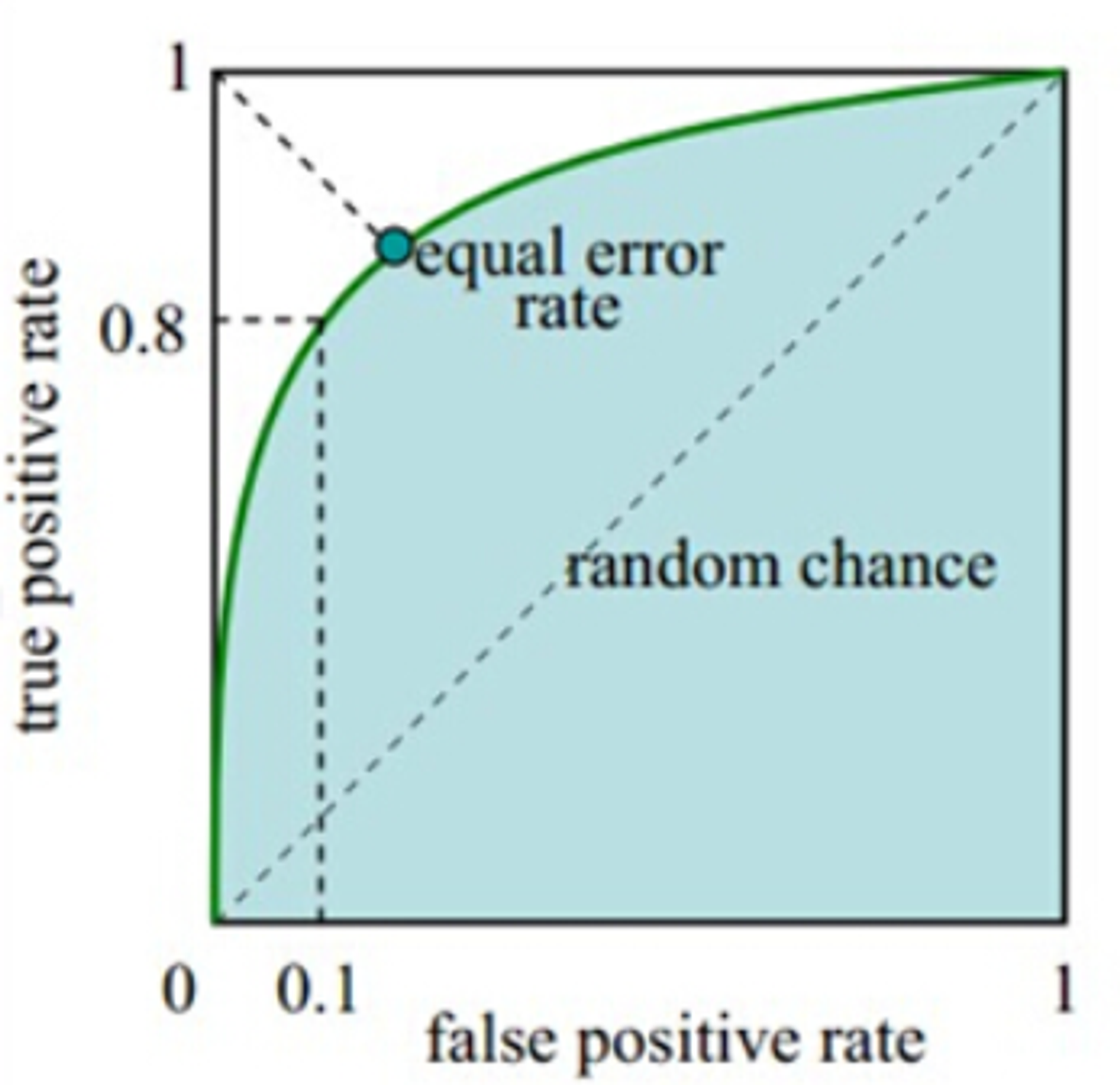
AUC分数解读:
- 当AUC=1的时候,表示模型能把类别完全分开
- 当AUC在0.5到1之间的时候,表示模型对一部分数据的区分能力较差
- 当AUC=0.5的时候,表示模型能力最差,完全随机的在预测数据。
- 当AUC在0到0.5之间的时候,表示模型能力也是较好,只是预测的结果符号相反。模型将正样本预测成了负样本,将负样本预测成了正样本。这个时候可以将模型的结果进行转换。
- 当AUC=0的时候,表示模型也能把类别完全分开,只是预测的结果符号完全相反。


2.7、ROC与PR的选择
- PR曲线更适用于不平衡类别分布的问题,关注模型对正类样本的预测性能。当正类样本较少或关注查准率较高时,PR曲线更能反映模型的性能。
- ROC曲线对于平衡类别分布的问题更为常用,关注模型在正负样本之间的区分能力。当正负样本比例接近或关注查全率和查准率的平衡时,ROC曲线更能展示模型的性能。
2.8、sklearn 实现
from sklearn.metrics import accuracy_score # 准确率 from sklearn.metrics import precision_score # 精确率 from sklearn.metrics import recall_score # 召回率 from sklearn.metrics import f1_score # f1 from sklearn.metrics import auc # 根据输入的不同,可以计算AUC-ROC,也可以计算AUC-PR from sklearn.metrics import roc_curve # ROC 曲线 from sklearn.metrics import roc_auc_score # AUC-ROC from sklearn.metrics import precision_recall_curve # PR 曲线 from sklearn.metrics import average_precision_score # AUC-PR y_true = np.array([0, 0, 1, 1]) y_pred = np.array([0.1, 0.4, 0.35, 0.8]) y_lable = (y_pred>=0.5)*1 # 将概率转换成标签 print(y_lable) # [0 0 0 1] # AUC 计算方法一,先获取曲线返回值,再算 AUC fpr, tpr, thresholds = roc_curve(y_true, y_pred, pos_label=1) # ROC 曲线,返回fpr, tpr,阈值。pos_label:正样本标签,如果是{0,1}则这里是1 roc_auc = auc(fpr, tpr) precision, recall, thresholds = precision_recall_curve(y_true, y_pred) # pr曲线,返回精确率,召回率,阈值 pr_auc = auc(recall, precision) # AUC 计算方法二,直接计算(计算的时候需要概率而不是标签) roc_auc = roc_auc_score(y_true, y_pred) # roc_auc pr_auc = average_precision_score(y_true, y_pred) # pr_auc # 其他指标计算 a = accuracy_score(y_true, y_lable) # 准确率,需要将概率转换成标签 p = precision_score(y_true, y_lable) # 精确率,需要将概率转换成标签 r = recall_score(y_true, y_lable) # 召回率,需要将概率转换成标签 f1 = f1_score(y_true, y_lable) # f1值,需要将概率转换成标签 print('roc_auc:',roc_auc) print('pr_auc:',pr_auc) print('准确率:',a) print('精确率:',p) print('召回率:',r) print('f1值:',f1)
三、多分类模型评估
3.1、混淆矩阵
假设有三个类别需要分类,现在训练了一个分类模型,对验证集的预测结果列成表格,每一行是真正的类别,每一列是预测的类别,这个列表矩阵即为混淆矩阵。如下所示,混淆矩阵中土黄色表示真实类别,蓝色表示预测类别,那么对角线上绿色值就表示预测正确的个数,某个绿色值除以当前行之和就是该类别的查全率(recall),除以当前列之和就是该类别的查准率(precision),对角线之和除以总和就是全局准确率(accuracy)。

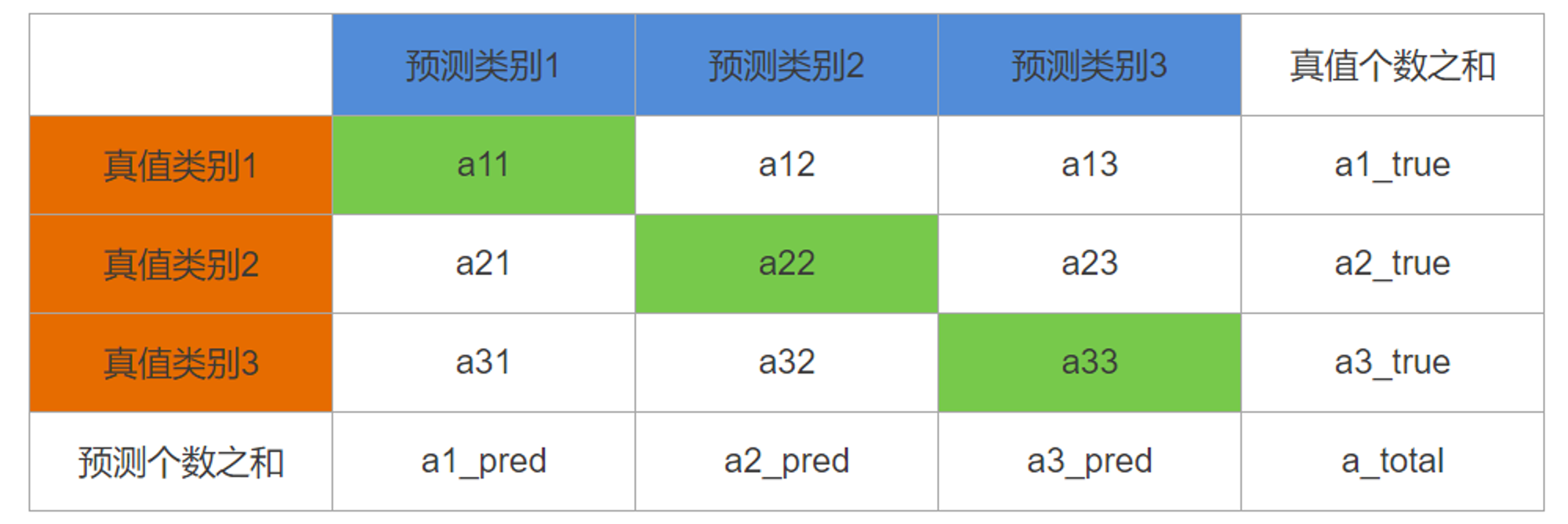
所以通过混淆矩阵就可以得出多分类的准确率、查准率、查全率。
但是,这里Accuracy度量的是全局样本预测情况,而对于Precision和Recall而言,每个类都需要单独计算其Precision和Recall。那如果要计算全局的Precision和Recall要怎么做呢?答案是求平均。
3.2、宏平均(macro-average)
直接将不同类别的评估指标(Precision/ Recall/ F1-score)加起来求平均,给所有类别相同的权重。该方法能够平等看待每个类别,但是它的值会受稀有类别影响。
3.3、加权平均(Weighted-average)
给不同类别不同权重(权重根据该类别的真实分布比例确定),每个类别乘权重后再进行相加。该方法考虑了类别不平衡情况,它的值更容易受到常见类的影响。
3.3、微平均(micro-average)
把每个类别的TP, FP, FN先相加之后,在根据二分类的公式进行计算。
需要注意的是,在多分类任务场景中,如果非要用一个综合考量的metric的话,宏平均会比微平均更好一些,因为宏平均受稀有类别影响更大。宏平均平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均平等考虑数据集中的每一个样本,所以它的值受到常见类别的影响比较大。
3.4、sklearn 实现
多分类的准确率、查准率、查全率、f1、auc 等指标实现方式与而分类相同,只是需要调整方法的average参数
a = accuracy_score(y_true, y_lable) # 准确率,需要将概率转换成标签 p = precision_score(y_true, y_lable, average=) # 精确率,需要将概率转换成标签 r = recall_score(y_true, y_lable, average=) # 召回率,需要将概率转换成标签 f1 = f1_score(y_true, y_lable, average=) # f1值,需要将概率转换成标签 # average:{‘micro’, ‘macro’, ‘samples’, ‘weighted’, ‘binary’} or None, default=’binary’ # micro:微平均 # macro:宏平均 # weighted:加权平均 # samples:含义未知 auc2 = roc_auc_score(y_true, y_pred, average=) # 计算的时候使用预测的概率 # average{‘micro’, ‘macro’, ‘samples’, ‘weighted’} or None, default=’macro’
四、聚类模型评估
4.1、方差比
方差比也叫CH(Calinski-Harabasz Index)指数,通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
from sklearn import metrics metrics.calinski_harabaz_score(X, y_pred)
4.2、轮廓系数
轮廓系数(Silhouette Coefficient)取值范围为[-1,1],取值越接近1则说明聚类性能越好,相反,取值越接近-1则说明聚类性能越差。
from sklearn import metrics metrics.silhouette_samples(X, y_pred, etric='euclidean') """ metric : 计算要素阵列中实例之间的距离时使用的度量。默认是euclidean(欧氏距离)。 如果metric是字符串,则必须是允许的选项之一metrics.pairwise.pairwise_distances。如果X是距离数组本身,请使用metric="precomputed"。 """
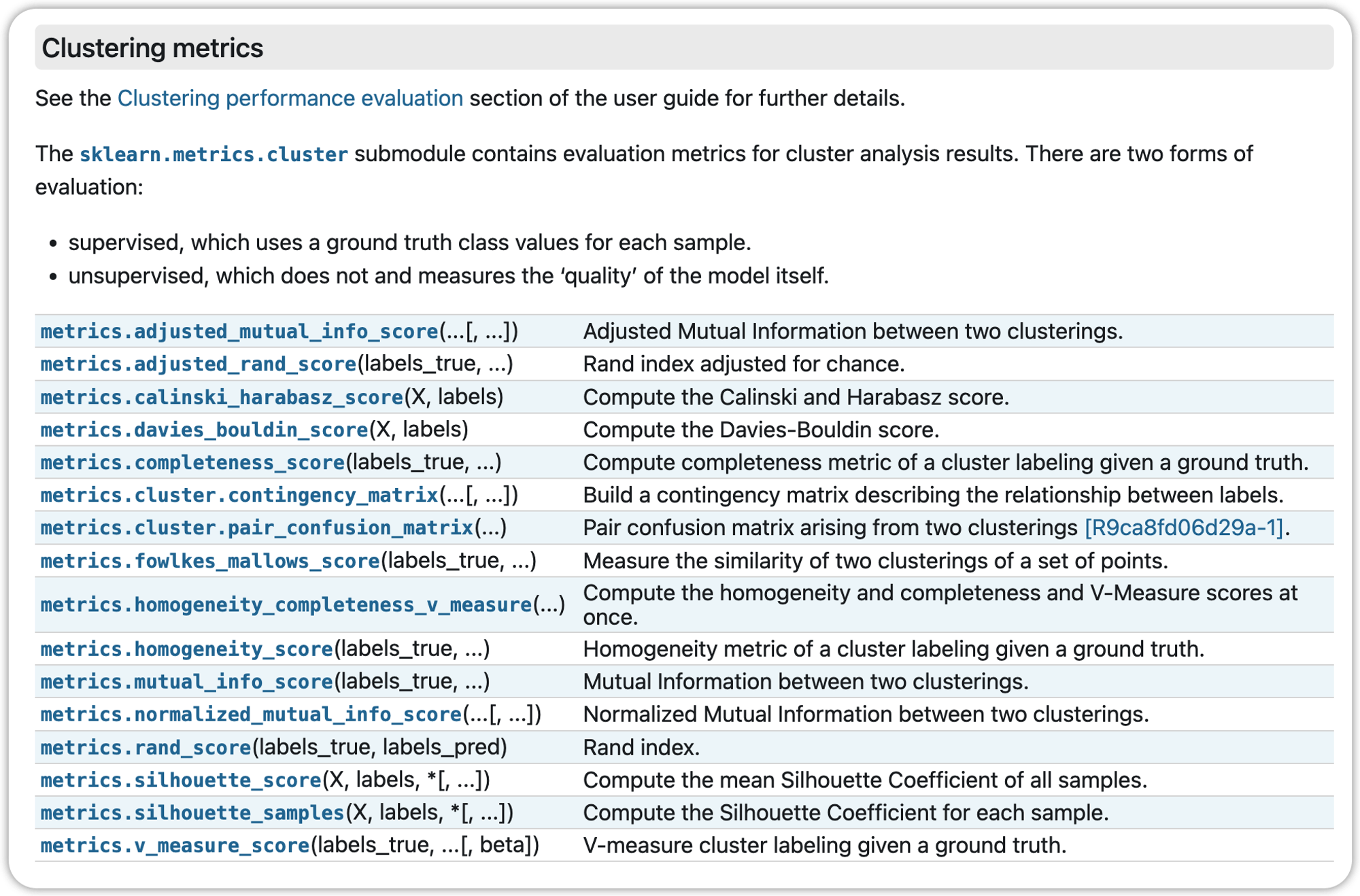
4.3、更多聚类评估指标
Sklearn

ChatGPT



