线性回归 | Linear Regression
type
Post
date
May 2, 2020
summary
回归是一种解题方法,或者说"学习"方法,也是机器学习中比较重要的概念。第一次见到这个词的朋友可能会问"回归?……回哪儿去?"
category
学习笔记
tags
线性回归
LR
回归算法
password
URL
Property
Jun 20, 2025 01:47 AM
1、线性回归
回归是一种解题方法,或者说"学习"方法,也是机器学习中比较重要的概念。第一次见到这个词的朋友可能会问"回归?……回哪儿去?",这也是我第一次见到这个词的疑问~
其实简单来说,回归就是一个“由果索因”的过程:当看到大量的事实所呈现的样态,推断出原因是如何的;在机器学习中就是:看到大量的数据是某种样态,推断出它们之间蕴含的关系是如何的。
比如说我们现在有大量的房源数据,这些数据的特征有:房屋面积,卧室数量,卫生间数量,楼层,到学校的距离,到医院的距离等等,同时每条数据还有一个label(也就是真实的房价)我们最终的目的是通过这些现有的数据去发现这么多数据的特征和label之间的关系,然后用这个关系去预测新的房屋特征,最终得出预测的房价。

那要怎么去找出特征和label之间的关系呢?这就得说说“线性回归”中的线性,其实就是初中我们就学过的直线方程: 当我们知道k(参数)和b(参数)的情况下,我随便给一个x我都能通过这个方程算出f(x)来。但是现在我们要先求出参数(k,b)才能使用这个方程进行预测,那要怎么求呢~
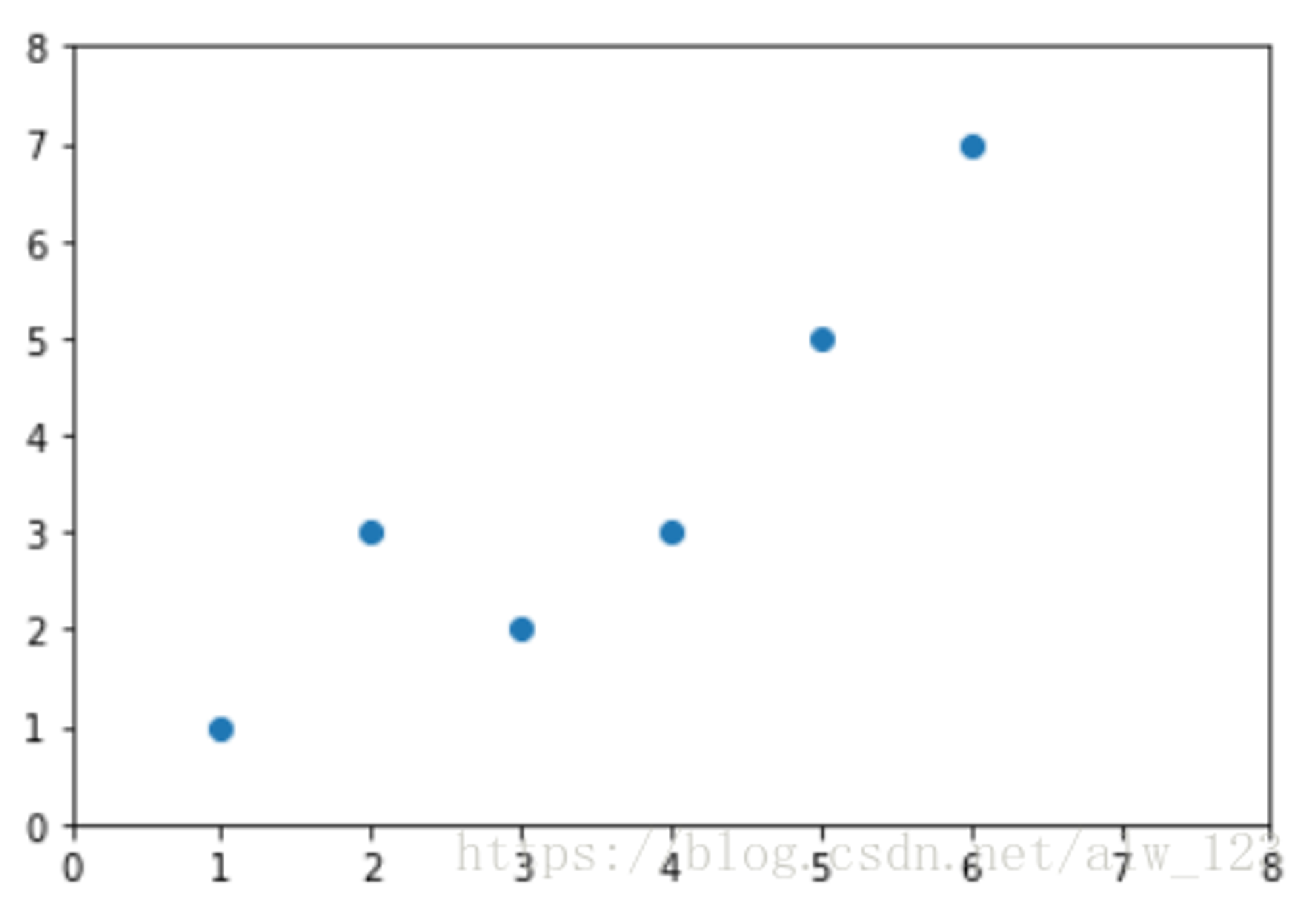
为了方便理解,我们先只看一个特征(房子面积)和lebel之间的关系;如左图:横坐标代表房子的面积,纵坐标代表房价。
然后呢,线性回归就是要找一条直线,并且让这条直线尽可能地拟合(也就是穿过)图中所有的数据点。那如果让1000个老铁来找这条直线就可能找出1000种直线来,如下图:

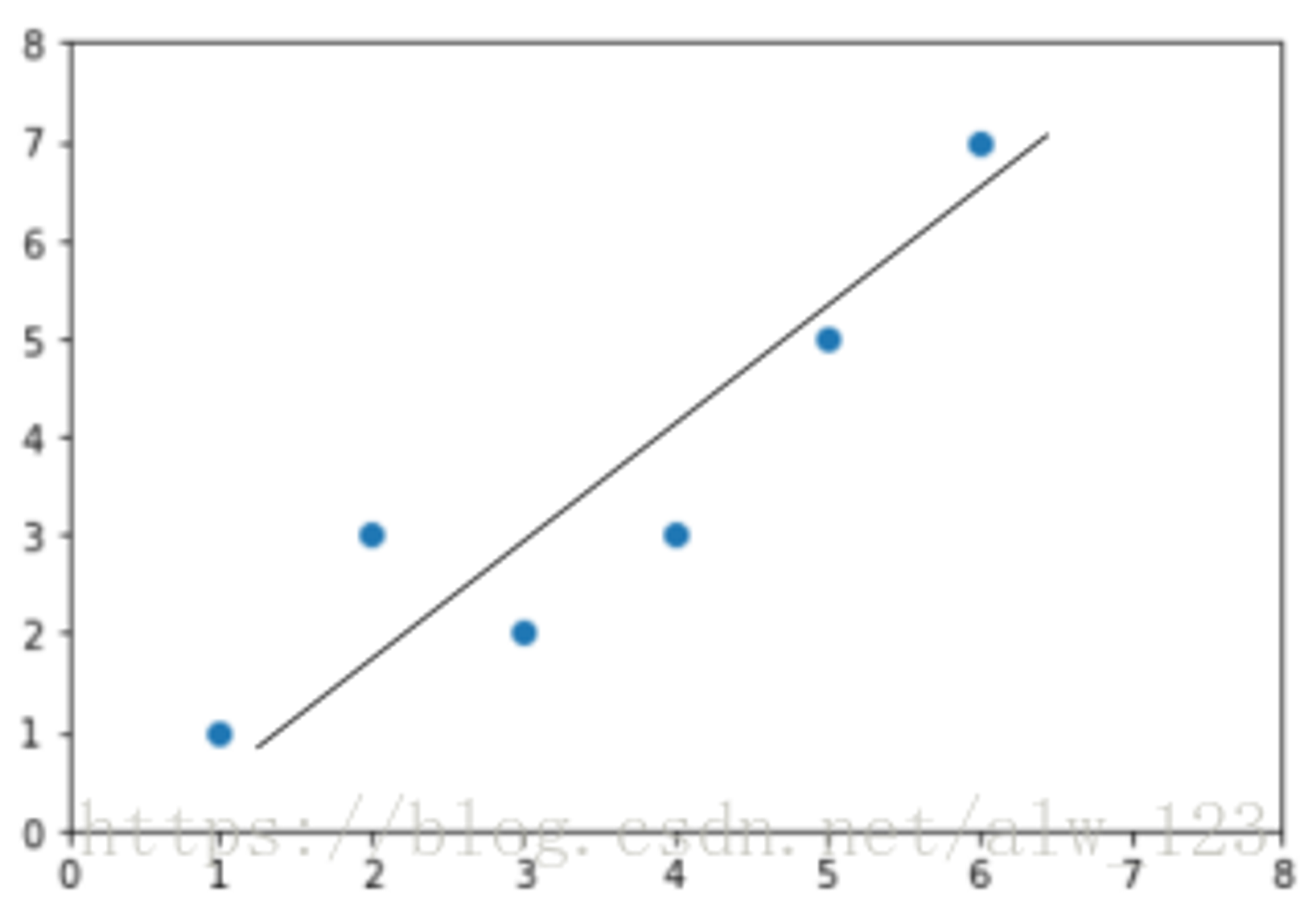

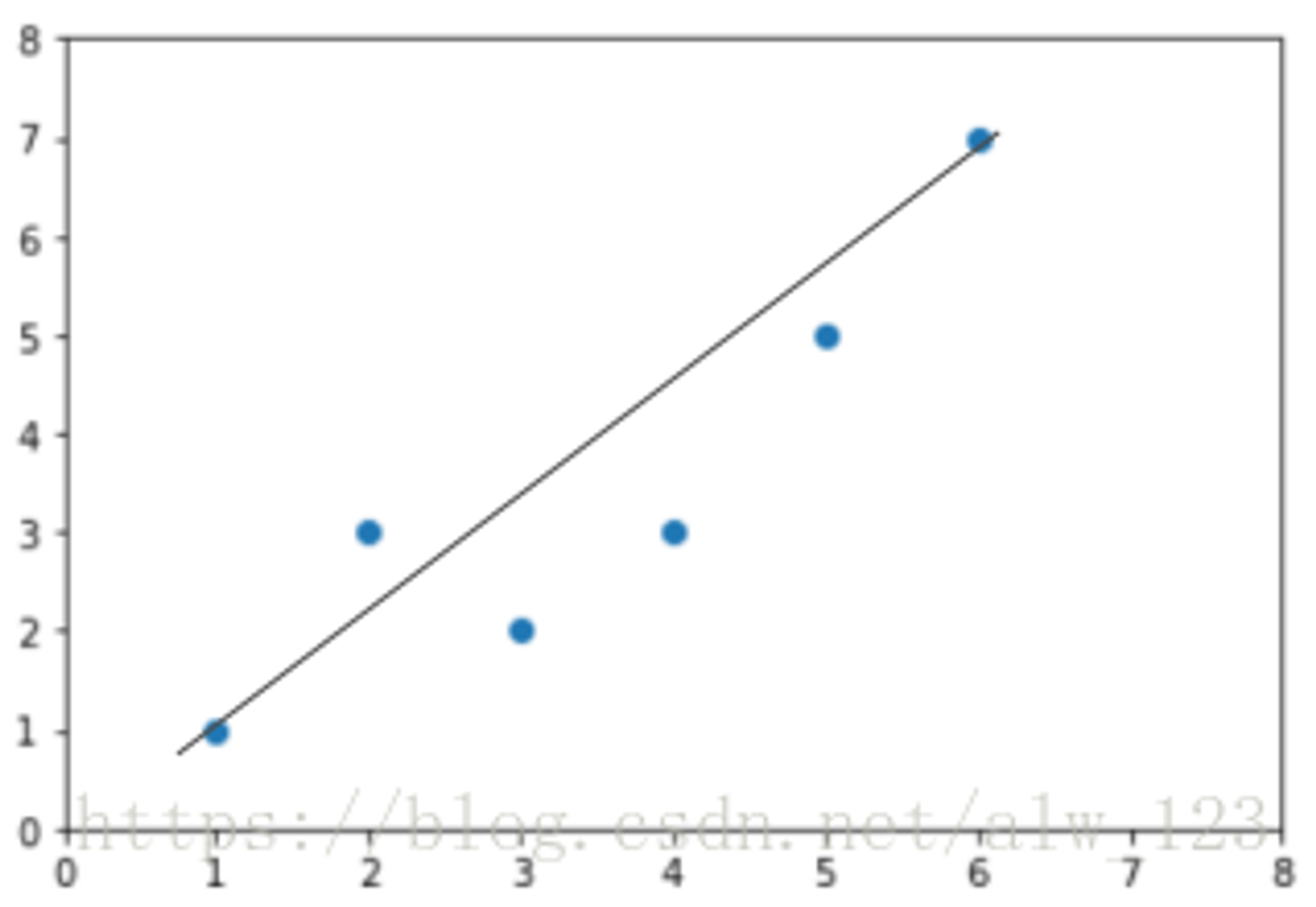

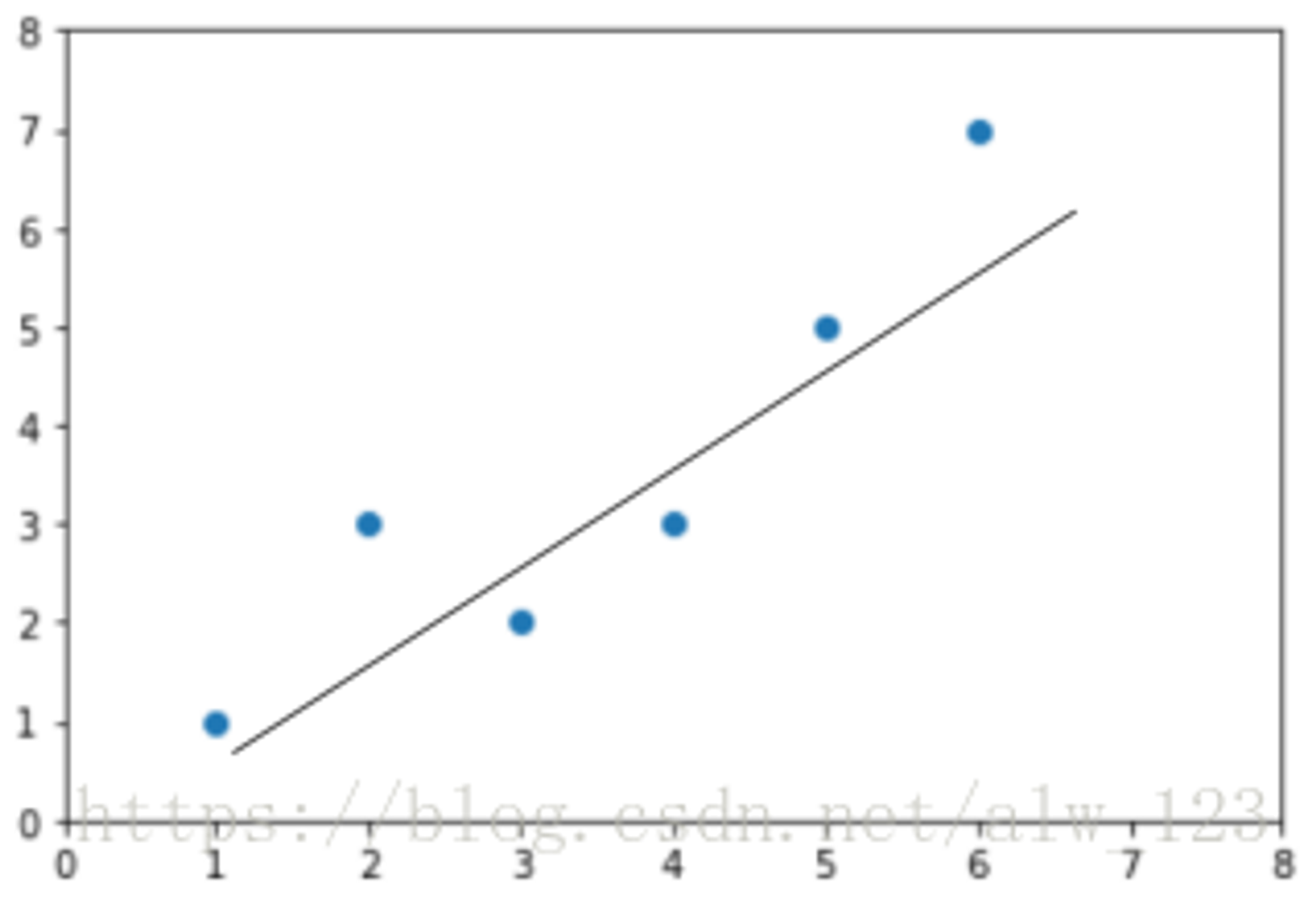
可以看到,通过已有的数据拟合一个函数的图像可以有很多种可能,但是我们只想要效果最好的哪一个。那怎么评价效果好不好,又要怎么找到最好的呢?这里我们通常会用损失函数来评价效果,用优化算法来找到使得“损失”最小的最优解。
损失函数通俗点说就是我们的预测值和实际值之间的差距, 所以损失函数的值越小,我们预测的结果和实际的结果就会愈接近
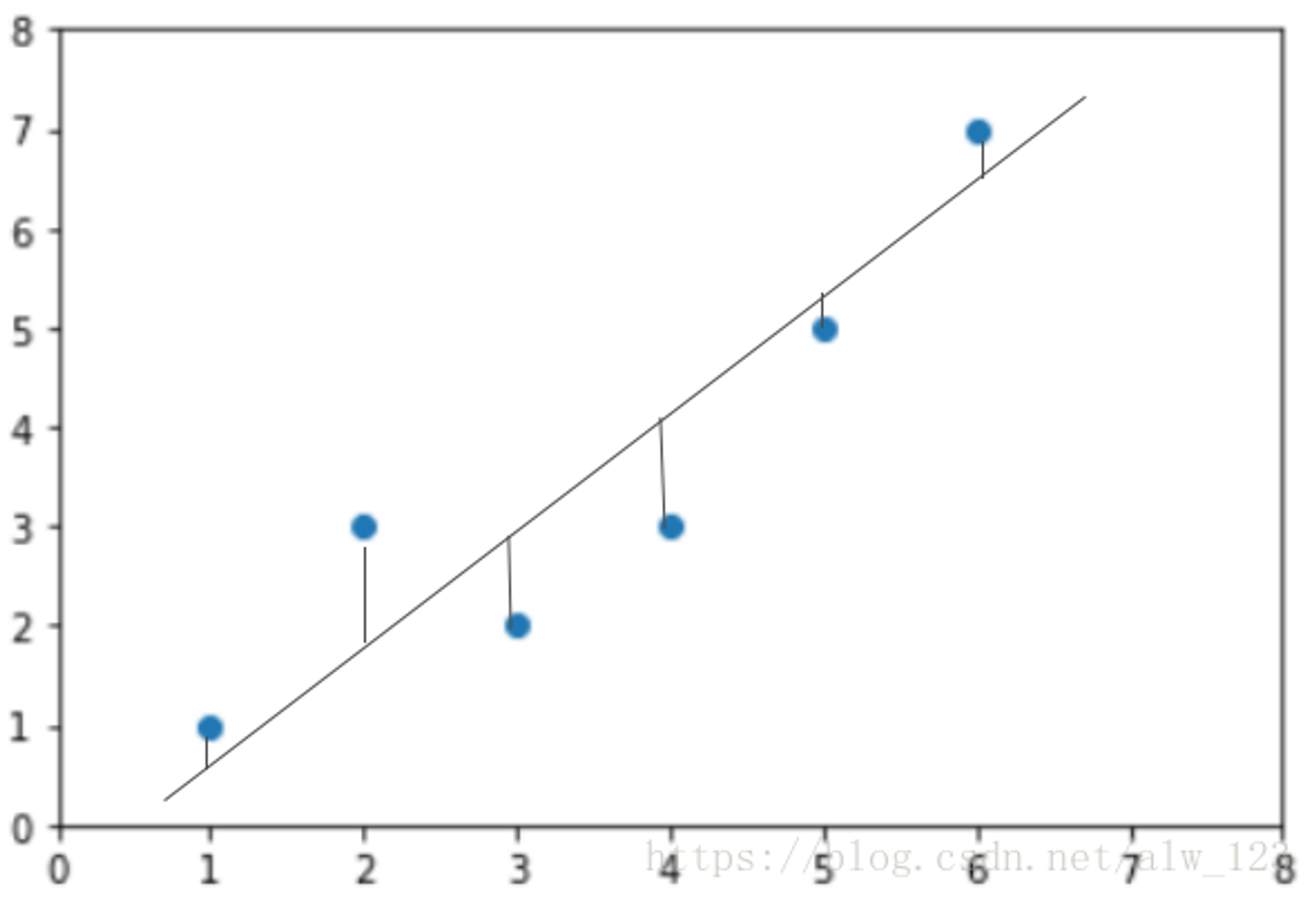
在图中蓝点表示真实值,直线表示预测值,我们把损失用图形表示出来就是这样
图中的竖线就是每个样本的预测值和真实值的误差。
线性回归通畅用EMS(均方误差)作为损失函数
将上图中的损失表示为数学表达式就是:
到目前为止,我们只看了一个特征和label之间的关系。其实在实际运用中一般不会只有一个特征,通常会有几十个甚至更多特征。
当我们考虑到所有特征时,第 i 个样本的是这样的:
这么长的式子看着就晕,简化一下:
上面的表达式里 只是一个样本的所有特征,所有样本的所有特征可以表示为
这时候我们真实值 y 也向量化并计算所有样本的损失:
由于X, θ, y都是矩阵, 运算后还是矩阵;矩阵的乘法是一个矩阵的行和另一个矩阵的列相乘,所以矩阵的平方就是该矩阵乘以他本身的转置矩阵
到这一步,损失函数的简化过程就结束了,这时候我们的目标是找到一个 θ 使得我们的损失函数 的值最小。
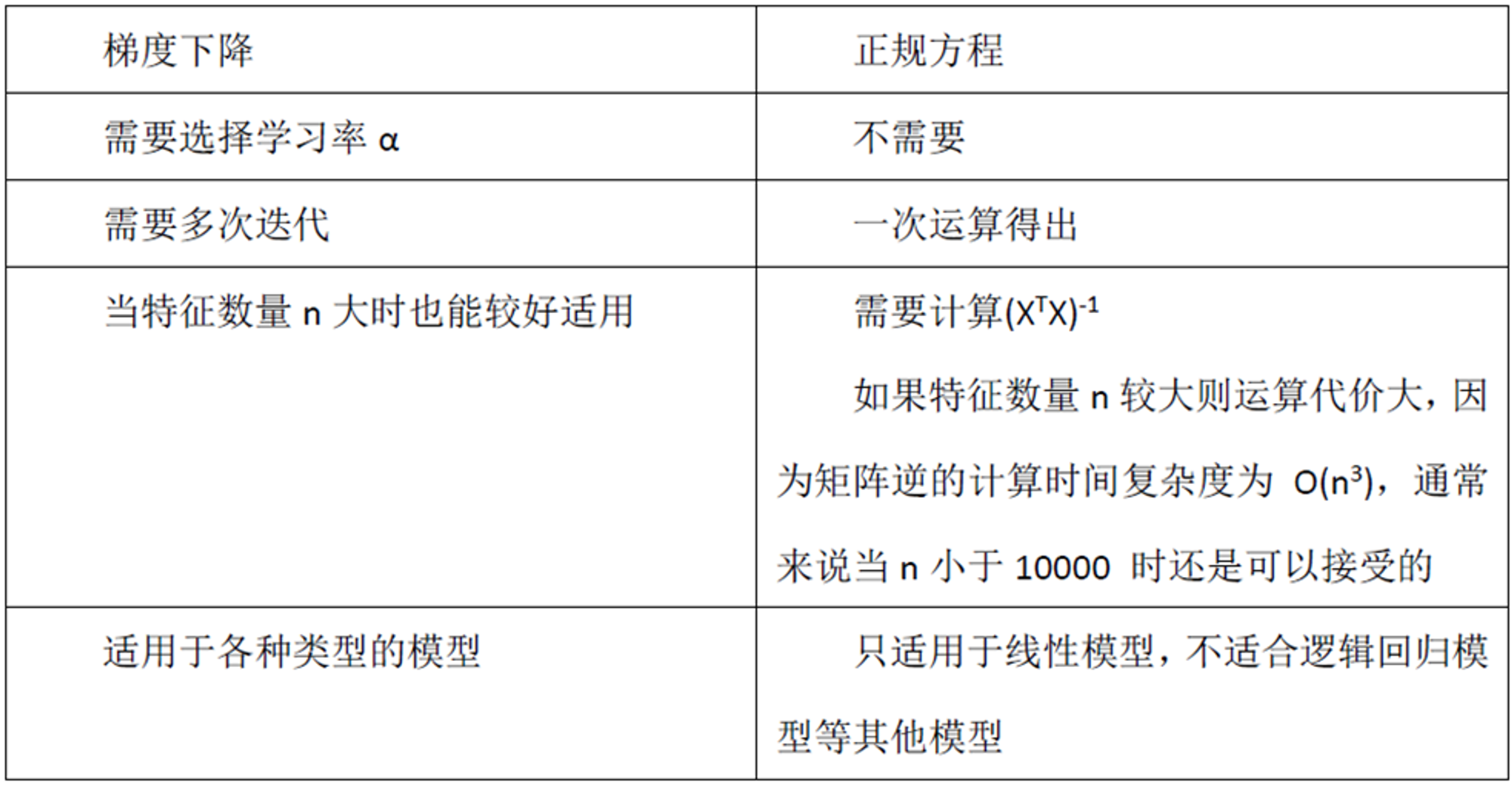
求解线性回归最常用的两个方法是:梯度下降法和最小二乘法
2、最小二乘法
最小二乘法的代数原理是用损失函数对多个参数求偏导,然后令偏导等于0,得到一个关于多个参数的方程组,求解方程组,就能求出我们想要的参数。
由于我们这里是将原式子向量化了,所以不用求方程组,只要令导数为0,求出来的就是所有参数组成的向量
令导数等于0,则:
至此,我们就用最小二乘法求出了最优参数
最小二乘法的缺点
首先,最小二乘法需要计算 的逆矩阵,有可能它的逆矩阵不存在,这样就没有办法直接用最小二乘法了,此时梯度下降法仍然可以使用。当然,我们可以通过对样本数据进行整理,去掉冗余特征。让 的行列式不为0,然后继续使用最小二乘法。
第二,当样本特征n非常的大的时候,计算 的逆矩阵是一个非常耗时的工作(nxn的矩阵求逆),甚至不可行。此时以梯度下降为代表的迭代法仍然可以使用。那这个n到底多大就不适合最小二乘法呢?如果你没有很多的分布式大数据计算资源,建议超过10000个特征就用迭代法吧。或者通过主成分分析降低特征的维度后再用最小二乘法。
第三,如果拟合函数不是线性的,这时无法使用最小二乘法,需要通过一些技巧转化为线性才能使用,此时梯度下降仍然可以用。
第四,讲一些特殊情况。当样本量m很少,小于特征数n的时候,这时拟合方程是欠定的,常用的优化方法都无法去拟合数据。当样本量m等于特征数n的时候,用方程组求解就可以了。当m大于n时,拟合方程是超定的,也就是我们常用与最小二乘法的场景了。
3、梯度下降求解
在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
算法步骤
1)确定当前位置的损失函数的梯度(对损失函数求导),对于θ向量,其梯度表达式:
2)用步长乘以损失函数的梯度,得到当前位置下降的距离,对应于前面登山例子中的某一步的距离。
3)确定θ向量里面的每个值,梯度下降的距离都小于ε,如果小于ε则算法终止,当前θ向量即为最终结果。否则进入步骤4.
3)确定θ向量里面的每个值,梯度下降的距离都小于ε,如果小于ε则算法终止,当前θ向量即为最终结果。否则进入步骤4.
4)更新θ向量,其更新表达式如下。更新完毕后继续转入步骤1
知道算法流程之后我们就要确定流程里面需要的参数
学习率的大小,影响迭代幅度。学习率偏小时,迭代次数多。学习率偏大时,迭代次数少,但有可能造成不收敛的情况。可以在保证收敛的前提下,尽量提升学习率,以减少迭代次数。
最常用的选择学习率的方法是按3倍调整,即:0.001、0.003、0.01、0.03、0.1、0.3、1 …… 按这个倍率进行测试,寻找能使 下降速度最快的学习率范围,确定范围后再对其进行微调。
特征缩放

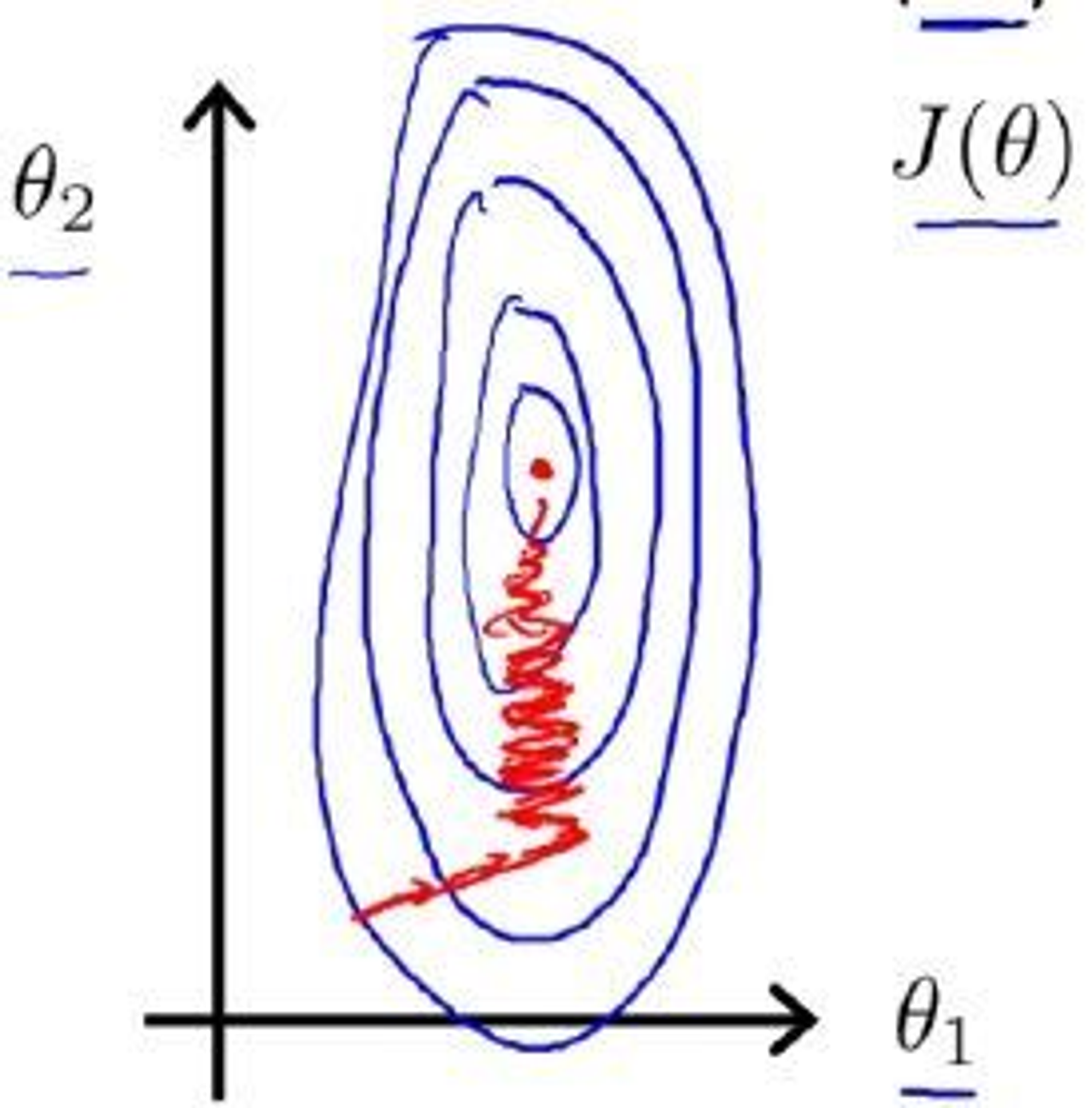

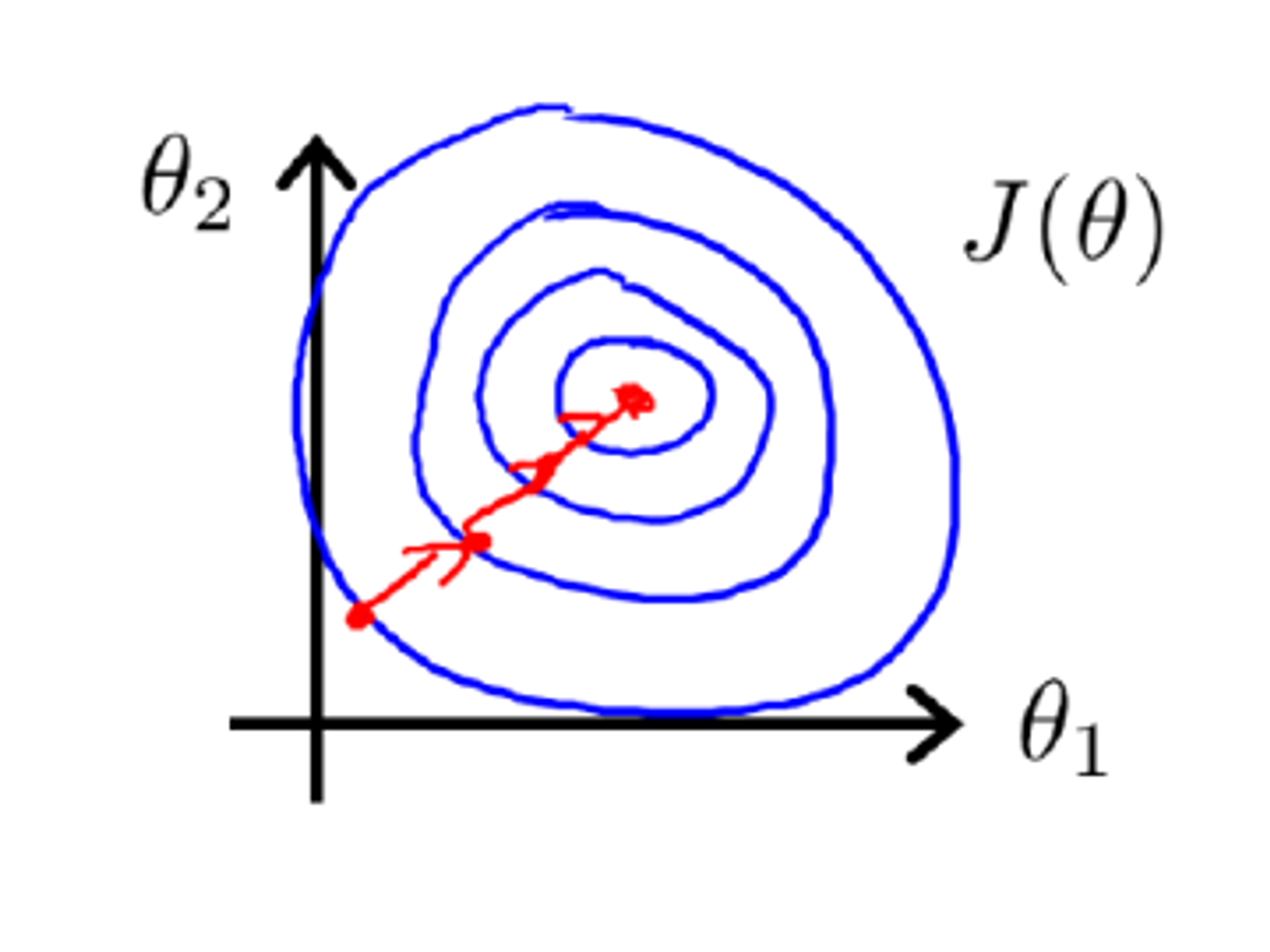


很明显,归一化处理前,代价函数的等高线图高又窄,在梯度下降过程中,需要反复迭代很多次,才能达到理想的位置,会花费较长的时间。归一化处理后,两个 feature 的数值大小处于相近的范围内,因此横纵坐标 和 两个参数的变化范围也变得相近,对 的影响不再有 feature 值在范围大小伤的影响,从而反映代价函数上。在等高线图上,梯度下降过程中变化受 x1 大小影响的 的变化减小了,变得和 x2 的变化趋势一致,从而等高线图近似圆形。
梯度下降法优缺点
在机器学习中的无约束优化算法,除了梯度下降以外,还有前面提到的最小二乘法,此外还有牛顿法和拟牛顿法。
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。