决策树 | Decision Tree
type
Post
date
Jun 20, 2020
summary
决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。决策树算法采用树形结构,使用层层推理来实现最终的分类。
category
学习笔记
tags
决策树
ID3
C4.5
CART
树模型
password
URL
Property
Jun 20, 2025 01:47 AM
一、概述
决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率分析的图法。决策树算法采用树形结构,使用层层推理来实现最终的分类。
决策树的结构:

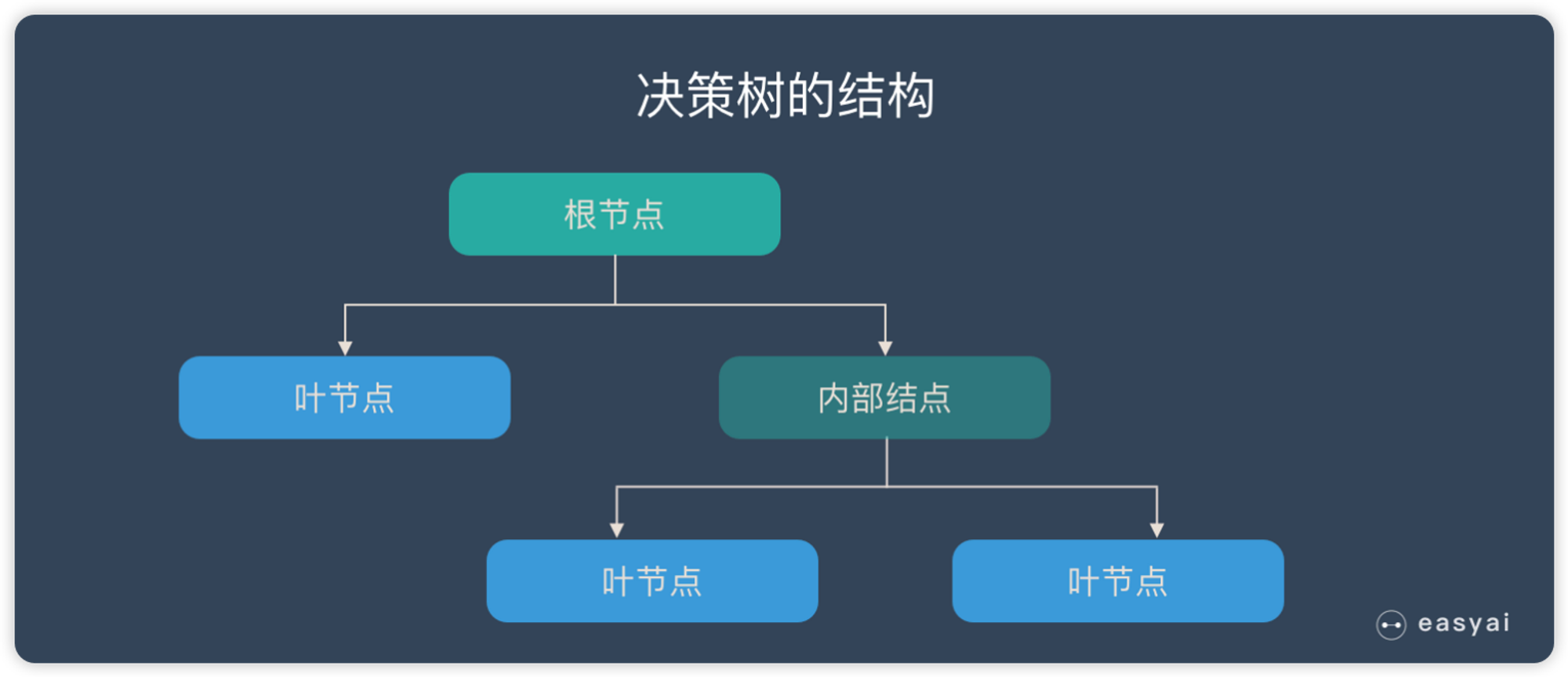
- 根节点:包含样本的全œ集
- 内部节点:对应特征属性测试
- 叶节点:代表决策的结果
预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
二、决策树算法
决策树算法中有三种基本算法: ID3算法,C4.5算法,CART算法(在sklearn中默认是使用CART算法);
2.1、ID3算法
ID3算法用信息增益来作为特征选择标准
对熵这个概念还不是很熟悉的童鞋可以借鉴一下CyberRep在知乎的回答
信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小。
衡量熵值的两个公式:
1: 信息熵公式:
条件熵:它度量了我们的X在知道Y以后剩下的不确定性
用目标值的信息熵 减去 知道属性比例后的目标值 的信息熵

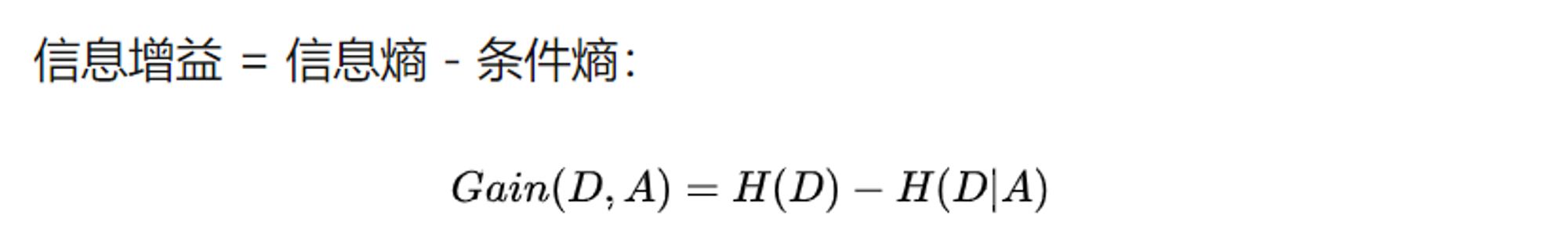
举个栗子:
如下图, 三个属性:日志密度, 好友密度, 头像是否真实, 判断账号是否真实

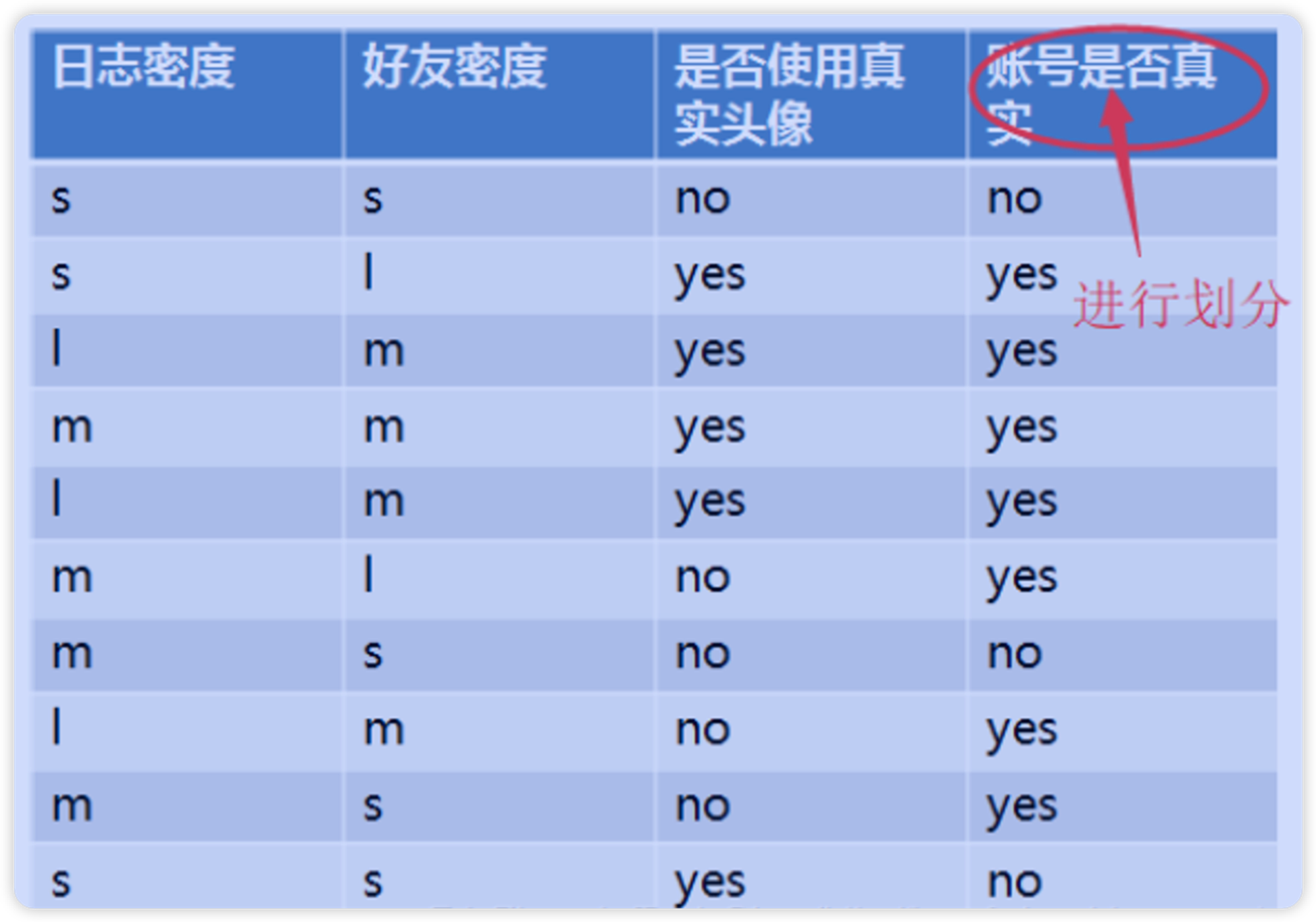
import numpy as np # 计算最后一栏的熵值(暂时不考虑属性的影响 - 期望信息) # 3个no,7个yes; H1 = -(0.3*np.log2(0.3)+0.7*np.log2(0.7)) H1 '''0.8812908992306927''' # 计算日志密度对期望信息的熵值 '''s -> 个数3 -> 概率0.3 -> 2个no,1个yesm -> 个数4 -> 概率0.4 -> 1个no,3个yesi -> 个数3 -> 概率0.3 -> 3个yes''' H2 = (0.3*(2/3*np.log2(3/2)+1/3*np.log2(3))) + (0.4*(1/4*np.log2(4)+3/4*np.log2(4/3))) + (0.3*np.log2(1)) print(H2) print('信息增益:', H1-H2) '''0.5999999999999999 信息增益: 0.28129089923069284''' # 计算好友密度对期望信息的熵值 '''s -> 个数4 -> 概率0.4 -> 3个no,1个yesm -> 个数4 -> 概率0.4 -> 4个yesi -> 个数2 -> 概率0.2 -> 2个yes''' H3 = (0.4*(3/4*np.log2(4/3)+1/4*np.log2(4))) + (0.4*np.log2(1)) + (0.2*np.log2(1)) print(H3) print('信息增益:', H1-H3) '''0.32451124978365314 信息增益: 0.5567796494470396'''
通过以上例子可以看出: 好友密度的信息增益比日志密度的信息增益大, 所以好友密度这一属性更适合作为根节点
2.2、C4.5算法
C4.5 算法最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
C4.5算法用信息增益比来作为特征选择标准
I(A,D)是信息增益, HA(D)是特征熵
其中n为特征A的类别数, Di为特征A的第i个取值对应的样本个数。|D|为样本个数。
2.3、CART算法
CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。
具体的,在分类问题中,假设有K个类别,第k个类别的概率为pi, 则基尼系数的表达式为:
对于个给定的样本D,假设有K个类别, 第k个类别的数量为Ck,则样本D的基尼系数表达式为:
三、不同决策树算法的优缺点
3.1、ID3
缺点
- ID3 没有剪枝策略,容易过拟合;
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
3.2、C4.5
C4.5使用的分类标准是信息增益率。
C4.5 相对于 ID3 的缺点对应有以下改进方式:
- 有后剪枝策略,能一定成都防止过拟合;
- 引入信息增益率作为划分标准,克服ID3 对特征数目的偏重;
缺点
- 剪枝策略可以再优化;
- C4.5 用的是多叉树,用二叉树效率更高;
- C4.5 只能用于分类;
- C4.5 使用的熵模型拥有大量耗时的对数运算,
3.3、CART
CART使用的分类标准是基尼系数。
CART 在 C4.5 的基础上进行了很多提升:
- C4.5 为多叉树,运算速度慢,CART 为二叉树,运算速度快;
- C4.5 只能分类,CART 既可以分类也可以回归;
- CART 使用 Gini 系数作为变量的不纯度量,减少了大量的对数运算;
3.4、对比
- ID3 和 C4.5 都只能用于分类问题,CART 可以用于分类和回归问题;
- ID3 和 C4.5 是多叉树,速度较慢,CART 是二叉树,计算速度很快;
- ID3 只能处理离散数据且缺失值敏感,C4.5 和 CART 可以处理连续性数据且有多种方式处理缺失值;从样本量考虑的话,小样本建议 C4.5、大样本建议 CART。
- ID3 没有剪枝策略,C4.5 是通过悲观剪枝策略来修正树的准确性,而 CART 是通过代价复杂度剪枝。
算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |
四、建立决策树
4.1、特征选择
特征选择决定了使用哪些特征来做判断。选择一个合适的特征作为判断节点,可以快速的分类,减少决策树的深度。决策树的目标就是把数据集按对应的类标签进行分类。
在训练数据集中,每个样本的属性可能有很多个,不同属性的作用有大有小。因而特征选择的作用就是筛选出跟分类结果相关性较高的特征,也就是分类能力较强的特征。
4.2、决策树的生成
选择好特征后,就从根节点触发,对节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;对每个子节点使用相同的方式生成新的子节点,直到信息增益很小或者没有特征可以选择为止。
4.3、决策树的修剪
决策树生成算法递归地产生决策树,直到不能继续下去未为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
五、决策树分类和回归
参数 | DecisionTreeClassifier | DecisionTreeRegressor |
特征选择标准criterion | 可以使用“gini”或者“entropy”,前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数“gini”就可以了,即CART算法。除非你更喜欢类似ID3, C4.5的最优特征选择方法。 | 可以使用“mse”或者“mae”,前者是均方差,后者是和均值之差的绝对值之和。推荐使用默认的“mse”。一般来说“mse”比“mae”更加精确。除非你想比较二个参数的效果的不同之处。 |
特征划分点选择标准splitter | 可以使用“best”或者“random”。前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。默认的“best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐“random” | ㅤ |
划分时考虑的最大特征数max_features | 可以使用很多种类型的值,默认是“None”,意味着划分时考虑所有的特征数;如果是“log2”意味着划分时最多考虑log2Nlog2N个特征;如果是“sqrt”或者“auto”意味着划分时最多考虑N−−√N个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。一般来说,如果样本特征数不多,比如小于50,我们用默认的“None”就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。 | ㅤ |
决策树最大深max_depth | 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。 | ㅤ |
内部节点再划分所需最小样本数min_samples_split | 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。 | ㅤ |
叶子节点最少样本数min_samples_leaf | 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。 | ㅤ |
叶子节点最小的样本权重和min_weight_fraction_leaf | 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。 | ㅤ |
最大叶子节点数max_leaf_nodes | 通过限制最大叶子节点数,可以防止过拟合,默认是“None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。 | ㅤ |
类别权重class_weight | 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的“None” | 不适用于回归树 |
节点划分最小不纯度min_impurity_split | 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。 | ㅤ |
数据是否预排序presort | 这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。 | ㅤ |
六、决策树应用
6.1、葡萄酒分类
import numpy as np from sklearn import datasets, tree from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt wine = datasets.load_wine() X = wine['data'] y = wine['target'] s1 = 0 s2 = 0 for i in range(300): X_train, X_test, y_train, y_test = train_test_split(X, y) model = DecisionTreeClassifier(max_depth=5) model.fit(X_train, y_train) s1 += model.score(X_train, y_train)/300 s2 += model.score(X_test, y_test)/300 print('训练准确度:', s1) print('测试准确度:', s2) _ = tree.plot_tree(model, filled=True) ''' 训练准确度: 0.9989473684210486 测试准确度: 0.9063703703703709 '''

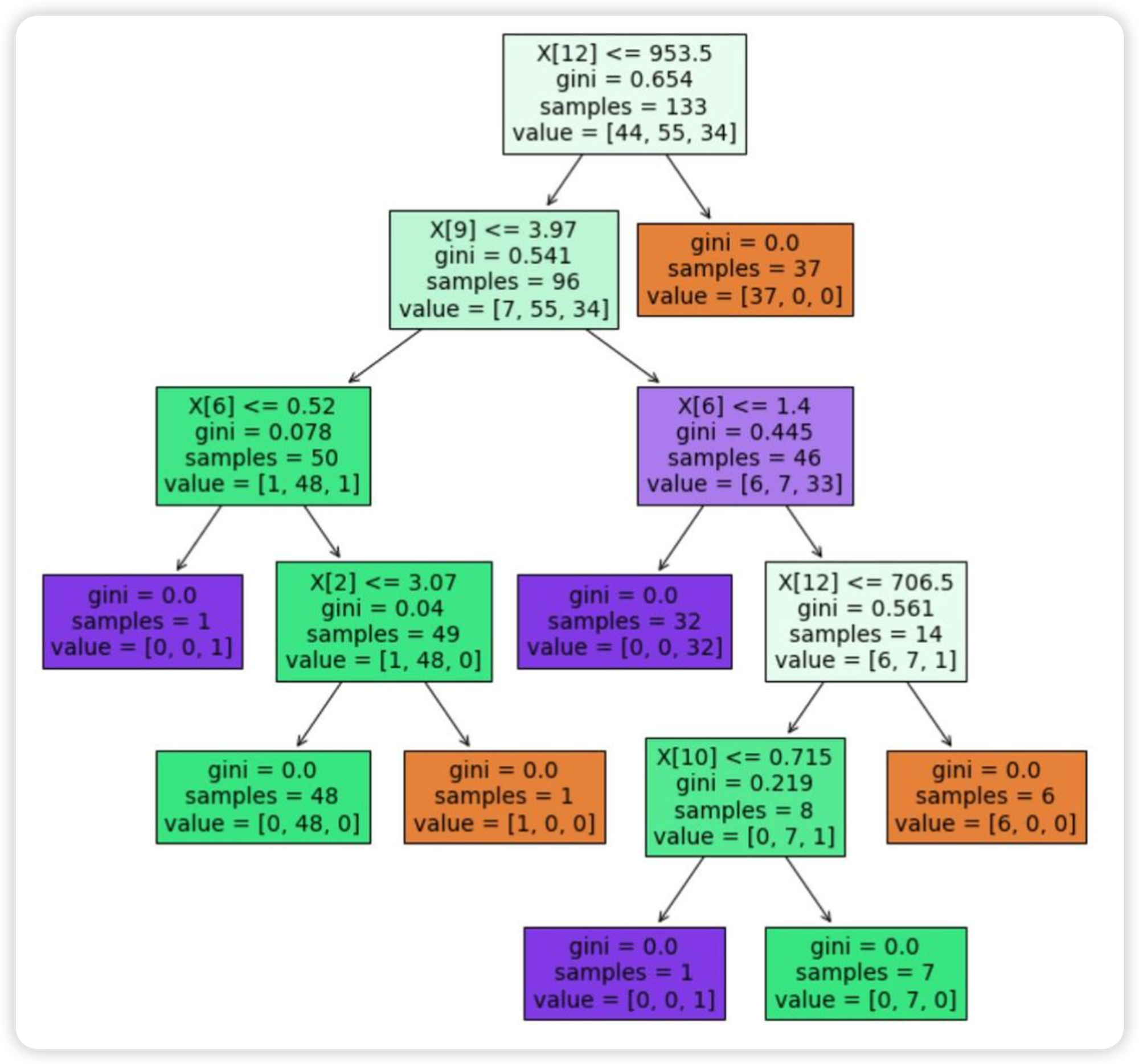
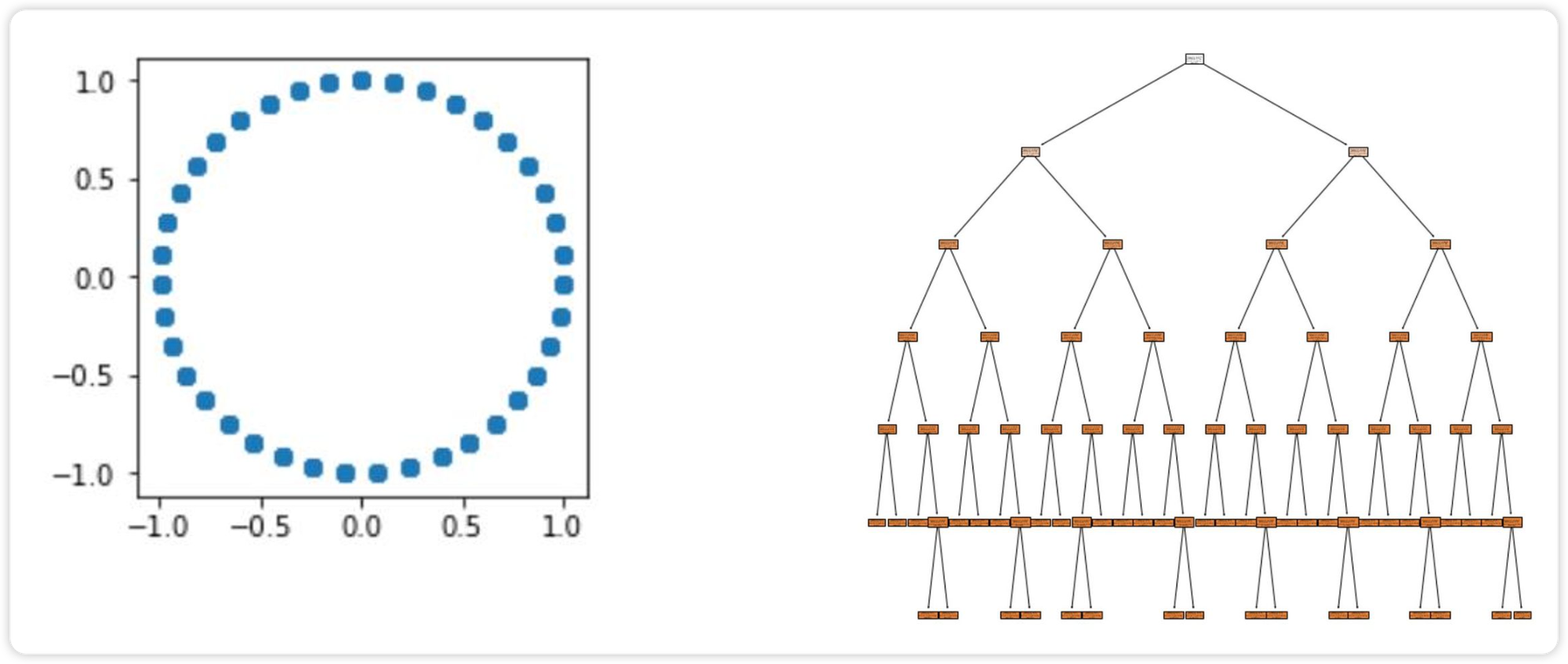
6.2、决策树回归
import numpy as np from sklearn.tree import DecisionTreeRegressor from sklearn import datasets, tree from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt X = np.linspace(0,2*np.pi, 40).reshape(-1,1) # 将数据变为二维数据 y = np.c_[np.sin(X), np.cos(X)] # 蒋两张数据组合 X_test = np.linspace(0,2*np.pi, 187).reshape(-1,1) model = DecisionTreeRegressor(criterion='mse', max_depth=None) # 当max_depth=1, 画出来的图像只有两个点 model.fit(X,y) # X有40个点 y_ = model.predict(X_test) # X_test是187个点 plt.figure(figsize=(3,3)) # 调节尺寸 plt.scatter(y[:,0], y[:,1]) # 绘制散点图 plt.figure(figsize=(12,12)) _ = tree.plot_tree(model, filled=True) # 绘制决策树 plt.savefig('./regrece.pdf', dpi=1024) # 保存决策树为pdf